MODELACIÓN DE SISTEMAS DE RECOMENDACIÓN APLICANDO REDES NEURONALES ARTIFICIALES
RECOMMENDATION SYSTEMS MODELING APPLIED ARTIFICIAL NEURAL NETWORKS
Fecha de envío: noviembre de 2012
Fecha de recepción: noviembre de 2013
Fecha de aceptación: octubre de 2013
Giovanny M. Tarazona B.
Ingeniero industrial, especialista en Ingeniería de Software, especialista en Proyectos Informáticos, Universidad Distrital “Francisco José de Caldas” (Colombia). Ph.D (c) en Sistemas Informáticos para Internet, Universidad de Oviedo (España). Docente investigador del Grupo de Investigación “Gicoecol”. Correo electrónico: gtarazona@udistrital.edu.co
Juan S. Chávez L.
Ingeniero industrial, Universidad Distrital Francisco José de Caldas (Colombia). Correo electrónico: jusechalo@hotmail.com
Roberto Ferro E.
Ingeniero electrónico, MSc. en Teleinformática, Universidad Distrital “Francisco José de Caldas”. Ph.D. (c) en Ingeniería Informática, Universidad Politécnica de Salamanca (España). Docente investigador y director del Grupo de Investigación Líder, Universidad Distrital Francisco José de Caldas. Correo electrónico: rferro@udistrital.edu.co
Resumen:
Este artículo desarrolla y describe un modelo para un sistema recomendador de productos en empresas de alquiler de películas. Al aplicarlo sistemáticamente, caracteriza los clientes y permite conocer sus tendencias de manera oportuna, veraz y fiable. Para ello se utiliza la metodología de redes neuronales artificiales y la teoría de la resonancia adaptativa, ya que la flexibilidad implícita de adaptarse a las necesidades corporativas incrementa la eficiencia de las transacciones en el ámbito de las aplicaciones web. Se usa la base de datos de contenidos de alquiler electrónico de películas vía web The Netflix Prize. La validación y simulación del modelo se codifica en MatLab®.
Palabras Clave:
sistemas de recomendación, redes neuronales, inteligencia de negocios, e-commerce, Netflix Prize
Abstract:
This paper develops and describes a model for characterizing customers and product recommender system in movie rental companies, so that, when applied consistently, allows to know the trends of users in a timely, accurate and reliable. To do this, we use the methodology of artificial neural networks and adaptive resonance theory, because its implicit flexibility to adapt to business needs increases the efficiency of transactions in the field of web applications. Use the database The Netflix Prize, and the validation and simulation was coded in MatLab ®.
Keywords:
Recommender systems, neural networks, business intelligence, e-commerce, Netflix Prize.
1. Introducción
En el entorno del empresariado colombiano, el comercio electrónico es una opción segura, en la medida que se invierta en recursos técnicos, físicos y humanos, así como en asumir estratégicamente esta herramienta para aumentar la capacidad de competir en un mercado cambiante que se sustenta en las nuevas tecnologías de la información y la comunicación [1].
Los sistemas de recomendación (RS) se han desarrollado para tratar de reducir parte del problema de la sobrecarga de información que se produce en la red. Basan su funcionamiento en un filtrado colaborativo (CF), proceso que ofrece recomendaciones personalizadas a usuarios activos de sitios web, en los diferentes elementos (productos, películas, fiestas, etc.) que pueden estar clasificados [2-4].
La generación actual de los métodos de recomendación se clasifica en las siguientes tres categorías principales: basados en el contenido, basados en colaboración y los enfoques híbridos de recomendación [5]. Entre las técnicas principales de los sistemas de recomendación, la de perfiles de usuario constituye la base. Al mismo tiempo, el trabajo en el mundo académico y la industria, desde la aparición de los sistemas de recomendación, se ha centrado en la creación de perfiles de usuario. La personalización de e-commerce utiliza la intención de una compra, hecha por un cliente en una aplicación de comercio electrónico, como información contextual [6-7]. Diferentes intentos de compra pueden dar lugar a diferentes tipos de comportamiento.
Se utiliza un PLC como controlador de bajo nivel, que es responsable para el control de la transportadora, el eyector, los sensores y la protección del sistema. Los resultados de la inspección serán transferidos al PLC, el cual controla la expulsión de botellas malas. Se ha demostrado que el algoritmo de control es capaz de alcanzar una alta tasa de inspección correcta, tanto para botellas defectuosas como para botellas buenas.
Para hacer frente a las distintas intenciones de compra, es menester construir un perfil de cliente independiente para cada compra del contexto, y estos perfiles separarlos para ser utilizados en la construcción de modelos independientes que predigan el comportamiento del cliente en contextos específicos y para segmentos específicos de clientes. Dicha segmentación contextual de los clientes es útil, porque da lugar a mejores modelos de predicción a través de diferentes aplicaciones de comercio electrónico [8]. Actualmente se desarrollan alternativas que buscan mejorar la predicción a través de elementos como la web semántica, la cual hace uso de agentes inteligentes para responder de mejor manera a los requerimientos de búsqueda de los usuarios. La web 3.0 integra de manera inmediata este concepto, con el fin de mejorar la calidad de los servicios que provee el modelo de comercio electrónico business to business (B2B) en el comercio electrónico, además de otros servicios [9-10].
Este artículo desarrolla y describe la construcción de un modelo de sistema de recomendación que clasifica la información de entrada, para crear una recomendación de producto, aplicado a la industria de contenidos [11,12], utilizando como agente inteligente el concepto de red neuronal artificial, y específicamente la teoría de la resonancia adaptativa. El texto se organiza así: en primer lugar se estudian los antecedentes teóricos de la resonancia adaptativa y la ART 1 [13-15]. Luego se describe la construcción del modelo: requerimientos, parámetros de información, arquitectura de red, entre otros. Posteriormente, se define el algoritmo alternativa, y luego se estructura la validación y simulación del modelo [16]. Finalmente, se exponen los resultados.
2. Antecedentes
2.1. Teoría de la resonancia adaptativa
Esta teoría, expuesta por Carpenter y Grossberg en 1987, presenta un diseño de tipología de red con el fin de dar respuesta a la necesidad de un modelo que fuera lo suficientemente estable como para preservar el aprendizaje pasado más significativo, y a su vez ser lo bastante flexible y adaptable para incorporar nueva información relevante si apareciera, dando solución a lo definido como el dilema de estabilidad-plasticidad [17,18].
En el anterior sentido, el diseño de las redes ART, combinado con la ley de aprendizaje bottom-up y la ley de aprendizaje top-down, dota a los sistemas con la capacidad de adquirir conocimiento a partir de la experiencia, donde los conceptos son creados de forma ascendente o bottom-up; es decir, en la medida que ingrese la información, el sistema establece una relación causa-efecto que se almacena en la memoria, indicándose si la información entrante ha favorecido o dificultado la consecución y el grado de logro de la meta. Esto por medio de una señal top-down. Si la nueva información favorece el logro de la meta, la señal es emitida para fomentar el almacenaje en la memoria de la nueva información. En caso de dificultar el logro, esta información es desestimada y, por lo tanto, no se emite señal alguna.
También se contempla el caso en donde, si se realizara una acción y se pasase a un estado desconocido, se almacena la información que represente este nuevo estado y se crea una regla que represente las condiciones necesarias para pasar a ese nuevo estado [19].
2.2. ART 1
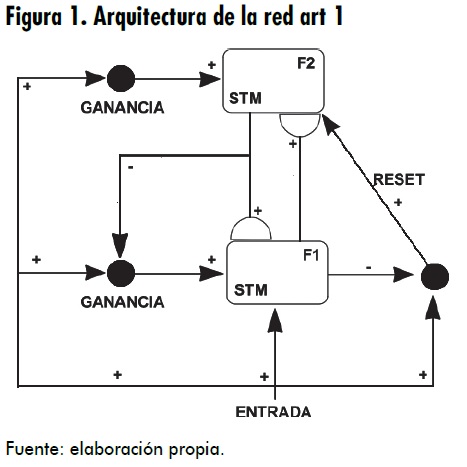
La arquitectura de la red ART 1 ver(figura 1) consta de un elemento F1 con N neuronas, cuyo número corresponderá con la dimensión de los patrones de entrada; y un elemento F2, que es una red competitiva multiplicativa de tipo on-center,1off-surround,2, con un número de neuronas que puede crecer a medida que aumenta la cantidad de información que está almacenando el sistema, representando cada neurona de este nivel una categoría.
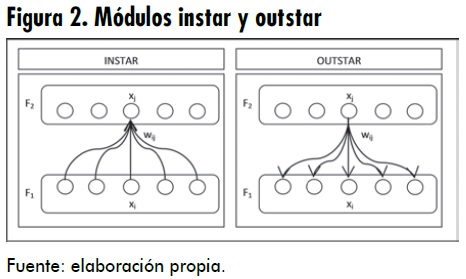
Esta red se encuentra compuesta de dos niveles, unidos entre sí por un módulo instar y un outstar. El modulo instar hace corresponder un estado de activación del nivel F1 con la activación de una neurona del nivel F2, mientras que el outstar es el dual del instar. Así, cuando se active una neurona en F2, este responderá con un estado de activación en F1 en el patrón asociado a esa neurona, por lo cual en el módulo instar el contenido accede a la memoria, mientras que en el outstar la memoria accede al contenido. En la figura 2 se muestra un esquema de estos módulos.
El aprendizaje de la red ART1 se fundamenta en la regla de los dos tercios (2/3), la cual basa el ciclo de comprobación de hipótesis y la autosensibilización del aprendizaje de la red, en respuesta a un patrón de la entradabottom-up. Las neuronas de F1 pueden ser lo suficientemente activadas como para generar una señal de salida hacia otras partes de la red, iniciando el proceso de comprobación de hipótesis. El proceso de búsqueda de una neurona adecuada de F2, solo termina cuando el prototipo concuerda suficientemente con la entrada, o cuando se selecciona una neurona que no había aprendido anteriormente. En este caso, se establece una nueva categoría, y los pesos top-down y bottom-up se adaptan siguiendo las reglas de aprendizaje respectivas.
3. Construcción del modelo
Teniendo en cuenta que la aplicación del modelo se limita a la industria de contenidos en el servicio de alquiler electrónico de películas para la compañía Netflix, vía web, partiendo de búsquedas con filtros en la base de datos de películas y la selección por parte del usuario de uno de los resultados, esta compañía desarrolló una herramienta para predecir si el usuario disfrutaría una película, con base en calificaciones anteriores de otras películas, con el fin de realizar recomendaciones personales y particulares de acuerdo al gusto de aquel.
Dado que el enfoque que la compañía aplica se basa en la calificación que el usuario realiza de la película, es frecuente que los usuarios no califiquen a conciencia, e incluso que no realicen dicha calificación, estableciéndose así un error del sistema utilizado, razón por la cual en busca de otras perspectivas y métodos se lanzó el concurso The Netflix Prize, donde se suministra información de los usuarios, los títulos de películas disponibles, su año de lanzamiento y el código interno, con el fin de que equipos de investigación puedan validar sus modelos y métodos, obteniéndose así herramientas útiles para la predicción de alquileres.
3.1. Parámetros del modelo y métodos
3.1.1. Definición de los requerimientos de información según el alcance
Los atributos que presentan las películas pueden ir desde el género al cual pertenecen, hasta la descripción específica del reparto. Se determinaron tres (3) atributos básicos que permitirán, no solo aumentar la información brindada al cliente en el proceso de alquiler, sino también proporcionar una mayor descripción de la selección que aquel lleva a cabo. Los atributos más importantes y los cuales ayudaran a generar una mejor recomendación son:
Primer atributo: género. Los géneros cinematográficos se clasifican según los elementos comunes de las películas que abarquen y aspectos tales como ritmo, estilo y el sentimiento que busquen provocar en el espectador. Algunos géneros a menudo son usados para formar subgéneros, y también pueden ser combinados para formar géneros híbridos. Con el fin de realizar una clasificación más amigable con el modelo, se decidió contemplar los géneros que se observan en la tabla 1.
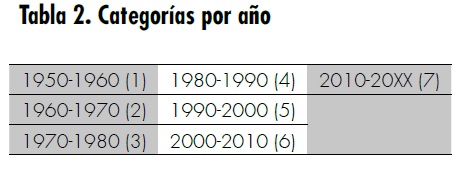
Segundo atributo: año. Los usuarios de este tipo de servicios realizan sus búsquedas con el fin de encontrar una película específica, usando como filtro el año de su estreno. Con el objetivo de presentar esta información a la red, se crearon unas categorías, en las cuales estarán clasificadas las películas por año (tabla 2).
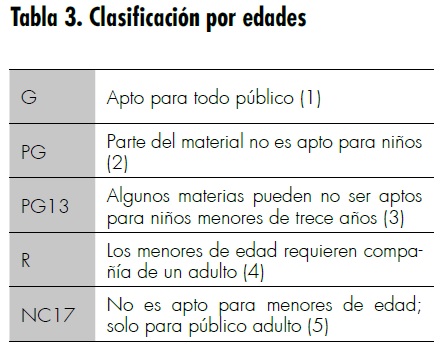
Tercer atributo: clasificación de acuerdo con la edad. En vista de la abundancia de material y de la gran accesibilidad que tienen este tipo de productos, es necesario crear una clasificación que sirva como filtro en el momento de presentar los resultados de recomendación al usuario. Por ello se consideró la clasificación por edades como uno de los atributos más importantes en el momento de la presentación de información a la red. Esta clasificación se ha tomado con base en la Asociación Cinematográfica de Estados Unidos (MPAA, por sus siglas en ingles),3 la cual plantea las categorías que se presentan en la tabla 3.
3.1.2. Definición de los parámetros de información de entrada
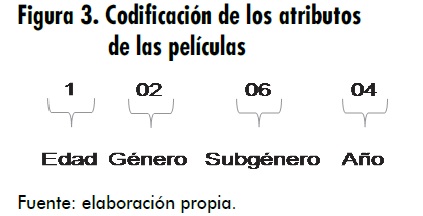
Con el fin de facilitar la introducción y extracción de información de la red, se creó una codificación que permite la identificación de una película específica, de acuerdo con los atributos presentados anteriormente. Esto permitirá una manipulación de la información de manera más sencilla y eficiente. La codificación se realizara como se muestra en la figura 3.
En el tipo de red neuronal ART 1 se trabajará con información de carácter binario. Esta codificación permitirá representar la ubicación del elemento uno (1) en un vector de información de entrada binario. Para ilustrar mejor esta representación tomaremos como ejemplo el anterior código. Este se representa vectorialmente así:

En donde las categorías estarán representadas de la siguiente manera:

De esta manera, se facilitará la identificación por parte del modelo de la categoría que creará o ya tiene creada la red.
3.1.3. Determinación de los parámetros necesarios según la red
Para el presente modelo y teniendo en cuenta que se desea que la sensibilidad del sistema para la creación de nuevas categorías no sea excesiva ni mesurada, el parámetro de vigilancia tendrá un valor posible entre 60 y 100% (0,6 < ρ < 1,0). Este parámetro será determinado con exactitud en la validación del modelo.
3.1.4. Establecimiento de la arquitectura de la red
La estructura básica de la red consta de tres secciones: la sección 1, conformada por un nodo que al usar el código transforma los atributos de la información de entrada en elementos legibles por la red. Luego esta información es enviada a la siguiente sección. La sección 2 comprende una red ART que tomará la información recibida del primer nodo, la procesará y la enviará finalmente a la sección 3, que está conformada por un nodo que de nuevo codificará la información de salida según los parámetros de codificación previamente presentados.
La red ART, por otra parte, contará con un número de neuronas de entrada igual a la dimensión del vector de información de entrada, es decir, que el número de neuronas de entrada será de 31. Además de esto, la red contará con una neurona Reset y una neurona ganancia, las cuales hacen parte esencial en este tipo de red. La descripción más detallada de los elementos que conforman esta red se hará en el siguiente apartado.
3.1.5 Determinación de las especificaciones de la red
Las redes de tipo ART cuentan en cada unión existente, entre neuronas, con pesos sinápticos. Estos pesos varían según la red aprende y es allí donde se encuentra almacenado su aprendizaje. A continuación se describe cada uno de estos pesos, cómo se determinan y qué función cumple cada uno.
Conexiones hacia arriba: las conexiones hacia arriba se realizan entre todas las neuronas pertenecientes a la capa de entrada j y todas las pertenecientes a la capa de salida i. Estas conexiones tiene un peso sináptico asociado, representados por el índice y sus valores iniciales están dados por:
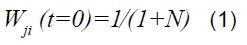
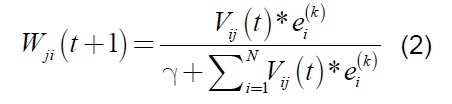
Donde N representa el número de neuronas de la capa de entrada, K el número de la información de entrada y “γ” un valor de normalización, generalmente 0,5.
Conexiones hacia abajo: de la misma manera que las conexiones hacia arriba, estas unen todas las neuronas de salida con todas las neuronas de entrada. Los pesos sinápticos asociados a estas conexiones están representadas por el índice Vij y sus valores iniciales están dados por:
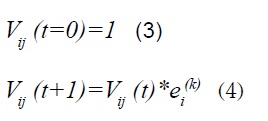
Conexiones hacia los lados: estas conexiones solo están presentes en las neuronas de salida y permiten la inhibición por parte de una neurona a sus vecinas, con lo cual se posibilita la clasificación acertada por parte de la red. Estas conexiones tienen asociado un peso sináptico igual a:
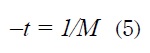
Donde M representa el número de neuronas de salida.
Conexiones hacia autorrecurrentes: cuando se presenta la competición entre las neuronas de salida, se deben tener en cuenta conexiones autorrecurrentes, que permitirán reforzar a la neurona ganadora, teniendo en cuenta su propio valor. Este valor siempre será de uno (+1), ya que representa la influencia de la neurona en sí misma.
Conexiones desde y hacia la ganancia: a la neurona de ganancia llegarán los valores de las neuronas de la capa de salida, con un peso sináptico asociado de –N, y los valores de la información de entrada con un peso sináptico asociado de +1. En este punto la neurona comparará los valores de entrada con los de salida, y el valor obtenido saldrá de la neurona de ganancia hacia las neuronas de entrada mediante conexiones con pesos sinápticos asociados de valor +1, las cuales permitirán fortalecer la activación de una cantidad de neuronas de entrada de acuerdo a la cantidad de neuronas de salida activadas, siguiendo la regla de los dos tercios.
Conexiones desde y hacia el Reset: los valores que recibirá la neurona de Reset provienen de las salidas de las neuronas de la capa de entrada, conectadas con peso sináptico asociado de -1 y de los valores de la información de entrada, conectados con peso sináptico asociado igual al valor del parámetro de vigilancia (ρ). La neurona compara estos valores y según el grado de similitud, establecido por el parámetro, envía señales inhibitorias de peso asociado muy grande(-α) a las neuronas de la capa de salida que no representen acertadamente la información de entrada.
3.1.6. Establecimiento del algoritmo del modelo
Para poder construir el modelo se deben establecer las características del proceso y el modo en el que este se desarrollará. Con el fin de facilitar su comprensión, lo hemos divido en tres módulos: el de lectura y codificación, el de clasificación y el de decodificación y recomendación. A continuación se presenta el proceso y la dinámica que llevarán a cabo estos tres módulos que conforman el sistema recomendador.
Módulo 1: lectura y codificación de la información. La información de entrada será presentada al modelo en el momento en que el usuario selecciona la película que desea alquilar. Siguiendo la codificación previamente presentada, se identifican los atributos de la película y se procede a convertirlos en los vectores determinados.
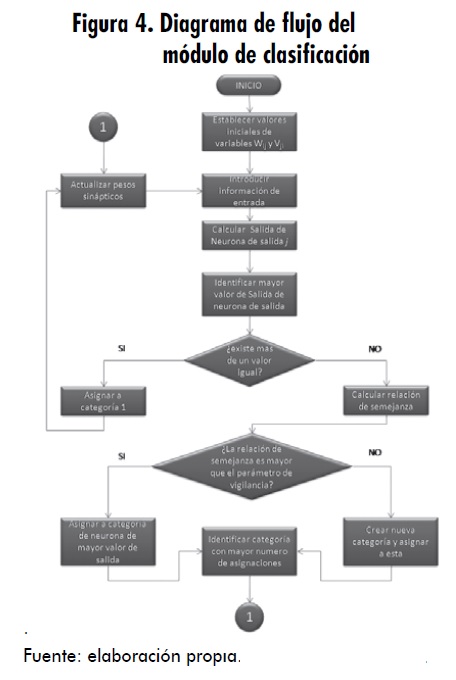
Módulo 2: clasificación de la información. Una vez recibida la información por parte del codificador, el modelo realizará la clasificación pertinente, utilizando como base la arquitectura previamente establecida. Se llevará a cabo el procedimiento que se presenta en la figura 4.
Se siguen los siguientes pasos:
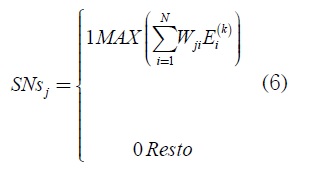
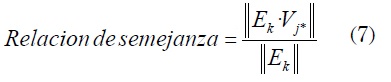
Donde

Módulo 3: decodificación y recomendación: una vez obtenida la clasificación, se tomará el valor almacenado, que identifica la categoría con mayor número de elementos asignados y se procederá a realizar la recomendación. En caso de que exista más de una categoría con el mismo número de elementos asignados, se tomará la categoría con la asignación más reciente.
Una vez identificada la categoría se procederá a decodificar el vector arrojado en la salida, siguiendo las pautas de codificación. El resultado de este procedimiento será la recomendación del modelo, la cual será aplicada como filtro de búsqueda de manera interna, ordenada por fecha de lanzamiento, obteniéndose como resultado los registros de películas asociadas a la categoría recomendada. En este punto es en donde radica el objetivo principal de este modelo.
4. Validación y simulación del modelo
Teniendo en cuenta las características anteriormente presentadas del modelo, el alcance de este proyecto y tomando como base de datos la proporcionada por el concurso The Netflix Prize, se realizó un tratamiento específico a dicha base de datos, con el fin de proporcionar información que fuese relevante para este proyecto, sin utilizar su totalidad. Por otro lado, se estableció la herramienta informática a utilizar, teniendo en cuenta factores tales como la capacidad de manejo de datos, la facilidad de integración con elementos externos y otros. En lo que sigue se describe la estructura de la base de datos, se especifican los factores de decisión anteriormente señalados y se presentan los resultados de la validación y simulación del modelo.
4.1. Aspectos generales del conjunto de datos
La base de datos utilizada en este proyecto fue obtenida directamente del concurso, con permisos para uso investigativo. Este conjunto de datos está compuesto por los siguientes elementos:
Con base en estos dos conjuntos de datos se realizaron consultas que llevaron a obtener un nuevo conjunto de datos, compatible con el modelo, el cual especificaba la siguiente información:
A partir de este conjunto de datos se procedió a realizar el tratamiento necesario para desarrollar a satisfacción la validación y simulación del modelo.
4.2. Tratamiento realizado a la base de datos
Debido a la gran cantidad de registros –exactamente 2 817 132– que se encontraban en la base de datos Netflix en su tabla qualifying, proporcionada para el concurso, se decidió filtrar esta a través de consultas, de manera que se mostrasen los registros de películas que fueron alquiladas más de ocho veces. Este valor fue elegido a través de consultas con expertos, en las cuales se recomendó realizar un muestreo por conglomerados del número de veces que se alquiló una película, escogiendo los dos más grandes y arrojando como resultado los registros de películas con repeticiones de alquiler de ocho y nueve veces.
Esta decisión se tomó con el fin de evaluar una cantidad de datos significativa, permitiendo a su vez establecer un número considerable y manejable de categorías en los usuarios.
El número de registros resultantes, es decir, el número de películas que fueron alquiladas más de ocho veces, fue de 86 de las 17 770 películas. El número de registros de alquiler que finalmente se obtuvo fue de 29 171. Este se almacenó en la consulta usuarios (alquiler = 9) perteneciente a la clase películas con código, perteneciente a la base de datos Netflix.
4.3. Selección de la herramienta de validación y simulación
Para seleccionar la herramienta más adecuada para la validación y simulación de este modelo, se decidió establecer como factores de elección los siguientes:
De acuerdo a los anteriores factores de elección, se decidió utilizar como herramienta de validación y simulación el software matemático Matlab® versión 7.8.0.347 (R2009a). Además de esta herramienta, se decidió utilizar, para el tratamiento de las bases de datos y el registro de resultados, el software de ofimática Microsoft Access® y Microsoft Excel®.
4.4. Parámetros de la validación y simulación
Para el desarrollo de esta validación y simulación solo se tuvo que tener en cuenta el parámetro de vigilancia (ρ), que representa la similitud de la información de entrada con los prototipos existentes y determina la forma en que se desarrollarán las categorías que creará la red.
Para este caso se consideró un valor de parámetro de vigilancia ρ = 0,6. Este se estableció con el propósito de constatar tanto el proceso de creación de nuevas categorías como la asignación a categorías ya existentes, ya que como se explicó anteriormente, este parámetro define la sensibilidad del sistema a la creación de categorías.
4.5. Desarrollo de la validación y simulación
El proceso de simulación se inició introduciendo los datos de entrada provenientes de la base de datos Netflix-Consulta Usuarios (alquiler = 9), perteneciente a la clase películas con código, en la matriz input. Una vez creada la matriz input, se procedió a cargarla en el espacio de trabajo de Matlab® y se ejecutó el archivo ejecutable .m, que contiene el código asociado al modelo.
Los resultados de la simulación y validación se dan en cuatro conjuntos de datos. Estos contienen la información relevante para este modelo y se detallan a continuación:
Estos conjuntos de datos serán exportados a una hoja de cálculo, con el fin de crear un registro de estos y para posteriores análisis [21].
6. Conclusiones
1.On-center (centro excitatorio) se refiere al proceso de realimentación positiva realizado por la neurona, que envía señales excitadoras a sí misma y a las vecinas próximas.
2. Off-surround (periferia inhibidora) se refiere al proceso dual, por el cual la neurona envía señales inhibitorias a las neuronas más lejanas.
3. Tomado de “What each rating means”, Motion Picture Association. Página oficial. Disponible: http://www.mpaa.org/ratings/ what-each-rating-means
Reconocimientos
Los autores expresan su agradecimiento al Grupo de Investigación Gicoecol, adscrito al Centro de Investigaciones y Desarrollo Científico (CIDC) de la Universidad Distrital “Francisco José de Caldas”, por la disposición de sus equipos e investigadores para la validación y simulación del modelo.
Referencias
[1] G. M. Tarazona, M. Gómez y C. Montenegro, “Buenas prácticas para implementación del comercio electrónico en pymes”, Visión Electrónica, vol. 6, no. 2, pp. 31-45, 2012.
[2] J. Bobadilla, A. Hernando, F. Ortega y J. Bernal, “A framework for collaborative filtering recommender systems”, Expert Systems with Applications, vol. 38, no. 12, pp. 14.609-14.623, nov. 2011.
[3] J. Buder y C. Schwind, “Learning with personalized recommender systems: A psychological view,” Computers in Human Behavior, vol. 28, no. 1, pp. 207-16, ene. 2012.
[4] K. Christidis y G. Mentzas, “A topic-based recommender system for electronic marketplace platforms,” Expert Systems with Applications, vol. 40, no. 11, pp. 4370-4379, sep. 2013.
[5] A. D. R. Oliveira, L. N. Bessa, T. R. Andrade, L. V. L. Filgueiras y J. S. Sichman, “Trust-based recommendation for the social Web,” IEEE Latin America Tranactions, vol. 10, no. 2, pp. 1661-66, mar. 2012.
[6] Z. Sevarac, V. Devedzic y J. Jovanovic, “Adaptive neuro-fuzzy pedagogical recommender,” Expert Systems with Applications, vol. 39, no. 10, pp. 9797-9806, ago. 2012.
[7] C. Porcel, A. Tejeda-Lorente, M. A. Martínez y E. Herrera-Viedma, “A hybrid recommender system for the selective dissemination of research resources in a technology transfer office,” Information Sciences, vol. 184, no. 1, pp. 1-19, feb. 2012.
align="justify">[8] G. Adomavicius y A. Tuzhilin, “Context-aware recommender systems,” Proceedings of the 2008 ACM conference on Recommender systems RecSys 08, vol. 16, no. RecSys, p. 335, 2008.
[9] G. M. Tarazona, L. Rodríguez, C. Pelayo-García y O. Sanjuan, “Model Innovation of process based on the Standard e-commerce International GS1,” International Journal of Interactive Multimedia and Artificial Intelligence, vol. 1, no. 7, p. 70, 2012.
[10] R. González, O. S. Martínez, J. Cueva, B. C. García-Bustelo, J. E. L. Gayo y P. Ordoñez, “Recommendation system based on user interaction data applied to intelligent electronic books,” Computers in Human Behavior, vol. 27, no. 4, pp. 1445-49, 2011.
[11] B. Fang, S. Liao, K. Xu, H. Cheng, C. Zhu y H. Chen, “A novel mobile recommender system for indoor shopping,” Expert Systems with Applications, vol. 39, no. 15, pp. 11.992-12.000, nov. 2012.
[12] J. Schafer, D. Frankowski, J. Herlocker y S. Sen, “Collaborative filtering recommender systems the adaptive web,” en The Adaptive Web, vol. 4321, p. Brusilovsky, A. Kobsa y W. Nejdl, eds., Berlín / Heidelberg: Springer, 2007, pp. 291-324.
[13] G. A. Carpenter y S. Grossberg, Search mechanisms for adaptive resonance theory (ART) architectures, 1989.
[14] T. P. Caudell y M. J. Healy, Adaptive resonance theory networks in the Encephalon autonomous vision system, vol. 2, 1994.
[15] L. G. Heins, D. R. Tauritz y M. June, “Adaptive resonance theory (ART): An introduction by,” Paragraph, pp. 1-15, jun.1995.
[16] M. Chen, A. A. Ghorbani y V. C. Bhavsar, Incremental communication for adaptive resonance theory networks, vol. 16, no. 1, pp. 132-44, 2005
[17] P. Wang. “Why recommendation is special?”. Working Notes of the AAAI Workshop on Recommender System, pp.111-13, Madison, jul. 1998.
[18] H. R. Resnick y P. Varian, “Recommender systems,”Communications of ACM, vol. 40, no. 3, pp. 56-58, 1997.
[19] H. Glotin, P. Warnier, F. Dandurand, S. Dufau, B. Lété, C. Touzet, J. C. Ziegler y J. Grainger, “An adaptive resonance theory account of the implicit learning of orthographic word forms,” Journal of Physiology Paris, vol. 104, no. 1-2, pp. 19-26, 2010.
[20] J. R. Hilera G. Redes neuronales artificiales: Fundamentos, modelos y aplicaciones, Madrid: Editorial Alfaomega, 390 p,, 2000.
[21] J. S. Chávez L. y E. Sierra M., Diseño de un modelo de caracterización de clientes y sistema recomendador de productos mediante una red neuronal artificial, para la industria de contenidos, usando la base de datos del concurso The Netflix prize, tesis para optar al título de ingeniero industrial, Universidad Distrital “Francisco Jose de Caldas”, Bogotá, Colombia 2010