
DOI:
https://doi.org/10.14483/22487638.12957Publicado:
01-10-2017Número:
Vol. 21 Núm. 54 (2017): Octubre - DiciembreSección:
InvestigaciónAnálisis multivariado para segmentación de clientes basada en RFM
Multivariate analysis for customer segmentation based on RFM
Palabras clave:
CRM, Multivariate analysis, RFM, Segmentation (en).Palabras clave:
análisis multivariado, CRM, RFM, segmentación (es).Descargas
Referencias
Chuang, H.M. y Shen, C.C. (2008). A study on the applications of data mining techniques to enhance customer lifetime value — based on the department store industry. International Conference on Machine Learning and Cybernetics (pp. 168-173). Kunming: China.
Durango, C.M.; Quintero, M.E. y Ruiz, C.A. (2015). Metodología para evaluar la madurez de la gestion del conocimiento en algunas grandes empresas colombianas. Tecnura, 19(43), 20-36. https://doi.org/10.14483/udistrital.jour.tecnura.2015.1.a01
Giraldo, F.; León, E. y Gómez, J. (2013). Caracterización de flujos de datos usando algoritmos de agrupamiento. Tecnura, 17(37), 153-166. https://doi.org/10.14483/udistrital.jour.tecnura.2013.3.a13
Khajvand, M.; Zolfaghar, K.; Ashoori, S. y Alizadeh, S. (2011). Estimating customer lifetime value based on RFM analysis of customer purchase behavior: Case study. Procedia Computer Science, 3, 57-63. https://doi.org/10.1016/j.procs.2010.12.011
Kim, S.Y.; Jung, T.S.; Suh, E.H. y Hwang, H.S. (2006). Customer segmentation and strategy development based on customer. Expert Systems with Applications, 31(1), 101-107. https://doi.org/10.1016/j.eswa.2005.09.004
Kohavi, R. y Parekh, R. (2004). Proceedings of the 2004 SIAM International Conference on Data Mining. Lake Buena Vista.
McCarty, J.A. y Hastak, M. (2007). Segmentation approaches in data-mining: A comparison of RFM, CHAID, and logistic regression. Journal of Business Research, 60(6), 656-662. https://doi.org/10.1016/j.jbusres.2006.06.015
Rueda, J.; Elles, C.; Sánchez, E.; González, A.L. y Rivillas, D.G. (2016). Identificación de patrones de variabilidad climática a partir de análisis de componentes principales, Fourier y clúster k-medias. Tecnura, 20(50), 55-68. https://doi.org/10.14483/udistrital.jour.tecnura.2016.4.a04
Santandreu, E. (2002). Manual del credit manager. Madrid: Ediciones Gestión 2000.
Shih, Y.Y. y Liu, C.Y. (2003). A method for customer lifetime value ranking — Combining the analytic hierarchy process and clustering analysis. Database Marketing & Customer Strategy Management, 11(2), 159-172. https://doi.org/10.1057/palgrave.dbm.3240216
Toro, E.M.; Pérez, L.P. y Bernal, M.E. (2007). Reducción de la dimensionalidad con componentes principales y técnica de búsqueda de la proyección aplicada a la clasificación de nuevos datos. Tecnura, 11(21), 29-40.
Cómo citar
APA
ACM
ACS
ABNT
Chicago
Harvard
IEEE
MLA
Turabian
Vancouver
Descargar cita
Recibido: 26 de febrero de 2017; Aceptado: 28 de agosto de 2017
Resumen
Contexto:
Para construir una gestión exitosa de relaciones con los clientes, las empresas deben comenzar con la identificación del verdadero valor de los clientes ya que esto proporciona información básica para implementar estrategias de marketing más dirigidas y personalizadas. El análisis RFM, un método clásico de análisis, permite mediante tres parámetros de evaluación, analizar el comportamiento de los clientes y establecer segmentos. La adición de un nuevo parámetro en la metodología tradicional es una oportunidad para refinar los posibles resultados de una segmentación de clientes, pues no sólo proporciona un nuevo elemento de evaluación para identificar los clientes más valiosos, sino que permite diferenciar y conocer aún mejor a los clientes.
Método:
La propuesta metodológica que se incluye en este artículo permite establecer segmentos de clientes utilizando un método RFM extendido con nuevas variables, seleccionadas mediante análisis multivariados.
Resultados:
La propuesta fue aplicada en una empresa en la que se probaron variables, como ganancia, porcentaje de ganancia y días de vencimiento de facturación, y se logró establecer una segmentación de clientes más detallada que el RFM clásico.
Conclusiones:
El análisis RFM es un método de amplio uso en la industria por su fácil comprensión y aplicabilidad. Este método puede ser mejorado con el uso de procedimientos estadísticos y nuevas variables, lo que permitirá contar con información más profunda sobre el comportamiento de los clientes y facilitará el diseño de estrategias específicas de marketing.
Palabras clave:
Análisis multivariado, CRM, RFM, Segmentación.Abstract
Context:
To build a successful relationship management (CRM), companies must start with the identification of the true value of customers, as this provides basic information to implement more targeted and customized marketing strategies. The RFM methodology, a classic analysis tool that uses three evaluation parameters, allows companies to understand customer behavior, and to establish customer segments. The addition of a new parameter in the traditional technique is an opportunity to refine the possible outcomes of a customer segmentation since it not only provides a new element of evaluation to identify the most valuable customers, but it also makes it possible to differentiate and get to know customers even better.
Method:
The article presents a methodology that allows to establish customer segments using an extended RFM method with new variables, selected through multivariate analysis..
Results:
The proposed implementation was applied in a company in which variables such as profit, profit percentage, and billing due date were tested. Therefore, it was possible to establish a more detailed customer segmentation than with the classic RFM.
Conclusions:
the RFM analysis is a method widely used in the industry for its easy understanding and applicability. However, it can be improved with the use of statistical procedures and new variables, which will allow companies to have deeper information about the behavior of the clients, and will facilitate the design of specific marketing strategies.
Keywords:
CRM, Multivariate analysis, RFM, Segmentation.INTRODUCCIÓN
El entorno empresarial es cada vez más competitivo y complejo, y la administración de relaciones con los clientes (Customer Relationship Management, CRM) es una estrategia competitiva para comprender a los clientes de una empresa (Kim, Jung, Suh y Hwang, 2006; Chuang y Shen, 2008). Pero la pregunta es: ¿En qué clientes se deben enfocar los esfuerzos para construir relaciones exitosas y competitivas, considerando que no todos ellos tienen la misma importancia para la empresa?
Para determinar este nivel de importancia, la utilización de técnicas de segmentación de clientes resulta útil y decisiva en la identificación de aquellos clientes que son realmente rentables, y permite focalizar más recursos en éstos, maximizando su valor, e igualmente, utilizando óptimamente recursos en función de captación, retención o recuperación de los mismos (Khajvand, Zolfaghar, Ashoori y Alizadeh, 2011). Las empresas deben entonces segmentar sus clientes en función de la capacidad de compra y otros condicionamientos, como su solvencia y garantía, debido a que la identificación del valor y la rentabilidad del cliente permiten desplegar estrategias de comercialización más específicas y personalizadas (Santandreu, 2002)
En los últimos años las técnicas de manipulación de las bases de datos han evolucionado a partir de modelos simples RFM (compras recientes (R), frecuencia de las compra (F) y monto de las compra (M)) (McCarty y Hastak, 2007). Por ejemplo, Shih y Liu (2003) propusieron utilizar ponderados como el ahp para dar pesos a las variables RFM. También, Khajvand et al. (2011) propusieron un método en el que asignaron pesos a las variables R, F y M, dependiendo de las características de la industria y adicionalmente agregaron la variable cantidad de ítems para segmentar clientes.
Aun cuando el RFM se ha utilizado por más de 50 años, sigue vigente entre los gerentes de mercadeo, ya que es fácil de entender, utilizar e implementar. El análisis RFM se basa en las siguientes observaciones simples que se han hecho una y otra vez a través de múltiples industrias (Kohavi y Parekh, 2004).
Los clientes que han comprado recientemente es probable que respondan mejor a los mensajes. También son más propensos a comprar nuevamente, en comparación con alguien que no ha comprado por un largo tiempo. Para algunas familias de productos donde se genera mucho entusiasmo por la compra, esto en efecto es más cierto.
-
Los compradores frecuentes son más propensos a comprar otra vez que los compradores poco frecuentes.
-
Los derrochadores suelen responder mejor que los que gastan poco.
Los tres atributos de comportamiento de RFM son extremadamente simples, ya que pueden ser fácilmente calculados para cualquier base de datos que tenga historial de compras, son fáciles de comprender, y aun así son poderosos en su capacidad predictiva (Kohavi y Parekh, 2004).
El análisis RFM ofrece un punto de partida para identificar el comportamiento de clientes; no obstante, según el tipo de industria o características específicas de una empresa, pueden presentarse otros parámetros de evaluación útiles, que permiten analizar de manera más precisa el comportamiento de éstos. En los últimos años, las técnicas de manipulación de las bases de datos han permitido incluir otras variables al análisis para poder comprender mejor al consumidor, como también crear atributos RFM para categorías específicas de familias de productos e industrias (McCarty y Hastak, 2007).
Según lo anterior, y considerando los estudios que han surgido alrededor de la técnica RFM, este artículo plantea mediante un caso de estudio, un método propuesto de segmentación a partir de la técnica ya existente RFM, que por su simplicidad se ajusta fácilmente a las posibles variables que puede tener un portafolio de clientes. Mediante la inclusión de nuevas variables a la técnica tradicional RFM, la propuesta busca ofrecer los mismos beneficios de la técnica original y adaptarse aún más a las necesidades o características propias de una empresa, como el tipo de productos, servicios, políticas y clientes. La inclusión de las nuevas variables se justifica utilizando técnicas de análisis multivariable, con el fin de conocer si las variables están correlacionadas, si son redundantes a los parámetros de la técnica RFM tradicional y si están aportando un valor agregado al método propuesto.
METODOLOGÍA
La metodología seguida para este trabajo consistió en varias etapas partiendo de la preparación de los datos, continuando con la definición, cálculo y selección de las variables a incluir, y finalmente, la agrupación de los clientes con dichas variables. A continuación, se describen los pasos seguidos en la investigación:
Preparación de los datos
Una primera instancia del proceso consiste en la revisión de la información existente de los clientes para identificar posibles errores o información no relevante para el análisis. El caso de estudio se desarrolló en una microempresa de la ciudad de Cali, dedicada a la manufactura y comercialización de productos desechables y plásticos. La empresa tiene un portafolio de 23 líneas de productos que comercializa a mayoristas y minoristas en varias ciudades del suroccidente del país. Tras la depuración, la base de datos de transacciones contó 304 clientes que, durante el periodo de análisis, 8 meses, realizaron 5962 transacciones.
Definición de las variables
Luego de la depuración, se calcularon las variables clásicas del modelo RFM, otras variables para realizar la selección. Estas fueron:
Reciente (R). Compras recientes. Mínimo tiempo en días transcurridos desde la última transacción hasta el final del periodo de análisis.
-
Frecuencia (F). Número de veces que cada cliente realizó una compra.
-
Monetario (M). Sumatoria de todas las transacciones del periodo.
Adicionalmente, teniendo en cuenta la información disponible y la opinión de los tomadores de decisiones en la empresa, se definieron otras tres variables para probar en la segmentación. Estas fueron:
-
Ganancia (G). Representa el valor que, de las ventas, realmente contribuye a la organización. Resulta de multiplicar la razón de margen contributivo que la empresa tiene calculado por familia de productos en el mes, por el valor de la compra realizada por el cliente durante ese mismo mes de esa familia de productos. Después se suman todas las ganancias por familia de productos, durante todo el tiempo de análisis para cada cliente como se muestra en la ecuación (1).
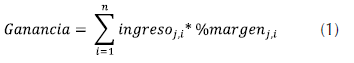
Donde i = mes, j = familia de producto
El margen contributivo está siendo calculado en la empresa por familia de productos como muestra la ecuación (2).
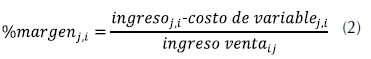
Donde el costo de variable se calcula de acuerdo con la ecuación (3).
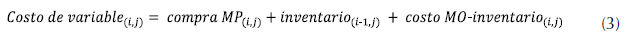
-
% de ganancia (%G). Esta variable representa la ganancia obtenida en términos de porcentajes por un cliente cuando compra. Se calcula como la relación entre la variable ganancia y la variable “monetario”.
-
Días vencidos (DV). El número de días vencidos (DV) por cliente hace referencia a la cantidad de días que el cliente tarde en cancelar el valor total de la compra realizada en determinada fecha, el conteo de dichos días comienza al finalizar el plazo que le es otorgado para la cancelación de la factura, el cual varía dependiendo de si la venta es a crédito o de contado o del sector donde se ubica el cliente.
Cálculo de las variables
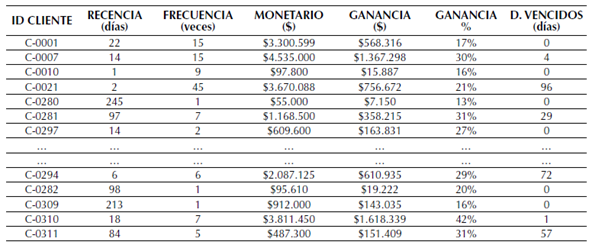
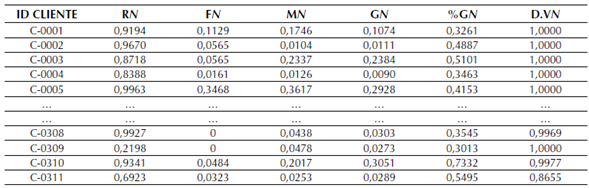
A partir de la descripción realizada anteriormente se procedió a calcular los valores de cada variable por cliente. En la tabla 1 se puede ver una fracción de la base de datos.
Fuente: elaboración propia.
Tabla 1: Valores iniciales de las variables R, F, M, G, %G, DV
Selección de variables representativas
En primera instancia, teniendo en cuenta que los datos se encontraban expresados en diferentes unidades de medidas, se normalizaron para tenerlos en forma homogénea, mediante fórmulas de costo y beneficio.
-
Normalización de las variables R y DV: dado que los valores de estas variables influyen negativamente en la calificación del cliente, es decir, a mayores valores de estas variables menor será su calificación, se utiliza la fórmula del costo dada por la ecuación (4).
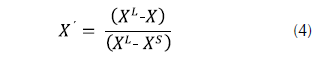
Donde:
X´ = valor normalizado de la variable
X = valor inicial de la variable
XL = máximo valor de la variable
XS = mínimo valor de la variable.
-
Normalización de las variables F, M, G y %G: como estas variables influyen positivamente en la calificación del cliente, es decir, a mayores valores de estas variables mayor será su calificación, se utiliza la fórmula del beneficio dada por la ecuación (5).
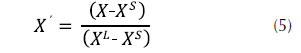
Donde:
X´ = valor normalizado de la variable
X = valor inicial de la variable
XL = máximo valor de la variable
XS = mínimo valor de la variable.
Tras aplicar las ecuaciones (4) y (5) se obtuvo la tabla 2, donde las cifras ya se encuentran normalizadas.
Fuente: elaboración propia.
Tabla 2: Valores normalizados de las variables RFM-G-%G-DV
Las variables pueden ser dependientes o independientes entre sí, de manera que la selección se hizo mediante técnicas de análisis multivariado para validar que las que se introdujeran en el modelo, realmente ofrecieran información adicional sobre los clientes y no hubiera redundancia. El análisis multivariado permite el estudio estadístico de datos de una población para resumirlos mediante nuevas variables, encontrar grupos, y clasificar nuevas observaciones en los grupos definidos (Toro, Pérez y Bernal, 2007).
De esta manera, las variables que dependieran de otras resultarían redundantes en el modelo de análisis y se descartarían. Las técnicas utilizadas fueron:
-
Matriz de covarianza. Permite identificar si hay relaciones entre variables. En este análisis, si la relación entre las variables es cero, se sabe que no hay relación entre las variables. La ecuación (6) permite calcular la relación entre las variables que es el promedio de los productos de las desviaciones de ambas variables con relación a sus medias respectivas.
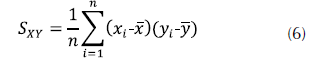
Como se puede ver en la tabla 3, al calcular las covarianzas, se encontró que en ningún caso la relación es cero, por tanto, aun cuando la relación existe, no se puede discernir si es lo suficientemente fuerte para afectar el análisis a realizar.
Fuente: elaboración propia.
Tabla 3: Matriz de covarianzas para medir la relación entre las variables RFM-G-%G-DV

-
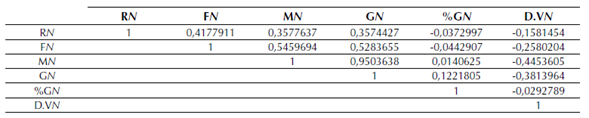
Matriz de correlaciones. Cuando una variable independiente se puede expresar como una combinación lineal de las otras, se considera que la co-linealidad es perfecta y entonces se puede omitir dicha variable. Los valores de la correlación varían entre 1 y -1, y cuando el valor de la correlación entre una variable x y se aproxima a 0, la relación entre las variables es nula. La matriz de correlaciones se desarrolló utilizando la ecuación (7).
Este análisis permitió identificar una fuerte relación (0,9503638) entre las variables M y G como se ve en la tabla 4.
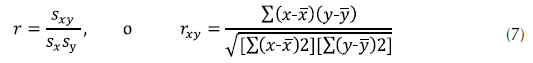
Fuente: elaboración propia.
Tabla 4: Matriz R, para medir la correlación entre las variables RFM-G-%G-DV
-
Co-linealidad. Para comprobar de forma concluyente qué variables en este caso de estudio son independientes y qué variables no, se realizaron dos mediciones más de la co-linealidad:
Tolerancia: se calcula de acuerdo con la ecuación (8).
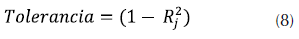
Donde j es el coeficiente de determinación de la variable Xj contra todas las demás X.
El coeficiente de determinación mide la proporción de variabilidad total de la variable dependiente y se obtiene a través de la ecuación (9).

Factor de inflación de la varianza: también conocido como FIV, se calcula de acuerdo con la ecuación (10).
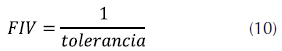
Como se puede apreciar en la tabla 5, al calcular la matriz FIV, entre las variables M y G, existe una colinealidad excesiva (10,3296623), es decir, las dos variables están fuertemente relacionadas.
Fuente: elaboración propia.
Tabla 5: Factor de inflación de las variables RFM-G-%G-DV
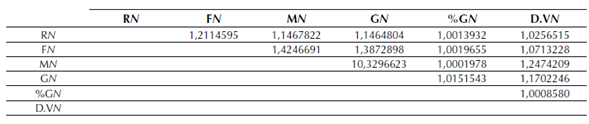
Con lo anterior se confirmó que existe una fuerte relación entre las variables M y G, por lo se podía eliminar una del modelo. La decisión fue extraer la variable G, ya que M es parte del modelo tradicional RFM y lo que se buscaba con el proyecto era explorar la adición de nuevas variables y no reemplazarlas. De esta manera, quedaron seleccionadas para realizar el análisis de los clientes, las variables: R, F, M, %G y DV.
Agrupación de los clientes
Con las variables a introducir ya seleccionadas y calculadas, se procedió a realizar la agrupación de clientes a través de K-means, con el fin de obtener los grupos con características de comportamiento similares que permitan detectar aquellos clientes más valiosos. El método K-means es una técnica particional no paramétrica que permite hacer conglomerados según un número decidido por el analista y es ampliamente utilizado en minería de datos (Rueda et al., 2016; Durango, Quintero y Ruiz, 2015; Giraldo, León y Gómez, 2013). Este método se desarrolló en diferentes pasos:
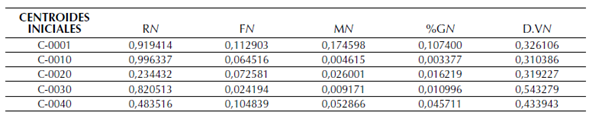
Decisión de los k elementos o número de clústers que se desea crear, que representan el centro inicial de cada clúster. Para el proyecto se definió contar con cinco grupos para los cuales se definieron los centroides iniciales, como se ve en la tabla 6.
Fuente: elaboración propia.
Tabla 6: Centroides iniciales de cada variable por grupo
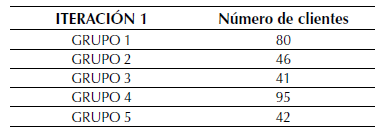
A continuación, cada una de las instancias es asignada al centro del clúster más cercano de acuerdo con la distancia euclidiana que le separa de él. Tras calcular las distancias euclidianas se asignaron los elementos al centro del clúster más cercano, por lo que se contó con una primera aproximación a los grupos. En la tabla 7 se aprecia el número de elementos que inician en cada grupo.
Fuente: elaboración propia.
Tabla 7: Número de clientes por cada grupo en la primera iteración
Para cada uno de los clúster así construidos se calcula el centroide de todas sus instancias y estos centroides son tomados como los nuevos centros de sus respectivos clústers. El proceso se repite con los nuevos centros de los clúster, hasta que no haya cambios en los grupos con cada iteración, lo que significa que los puntos centrales de los grupos se han establecido y permanecerán inalterables. En la tabla 8 se presentan los resultados de la última iteración en la que no hubo cambios.
Fuente: elaboración porpia
Tabla 8: ultima iteración del clustering

RESULTADOS
Finalmente, con los grupos establecidos, se calculó la calificación de cada grupo, como la sumatoria del promedio del valor de las variables normalizadas de los clientes que se encuentran en dicho grupo. Los grupos con mejores calificaciones fueron los 1 y 4, mientras que el grupo con la más baja calificación fue el 3, como se puede ver en la tabla 9.
Fuente: elaboración propia
Tabla 9: Numero de observaciones arrojadas por el grupo

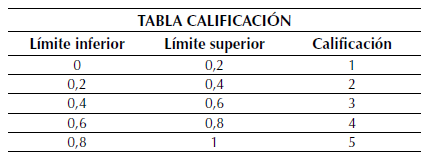
Con el interés de establecer una calificación por intervalos, se estableció una escala con cinco niveles entre los límites, inferior y superior de las variables normalizadas, como se ve en la tabla 10.
Fuente: elaboración propia
Tabla 10: Valor calificación por quintiles
Para calificar las variables de cada grupo, se estableció que calificaciones de 1 y 2 corresponderían a una calificación baja; calificación de 3 corresponde a una media, y calificaciones de 4 y 5 corresponden a una alta. La tabla 11 resume los resultados, en orden descendente, para cada grupo en función del rango de cada variable de análisis.
Fuente: elaboración propia
Tabla 11: Resumen resultado de los grupos
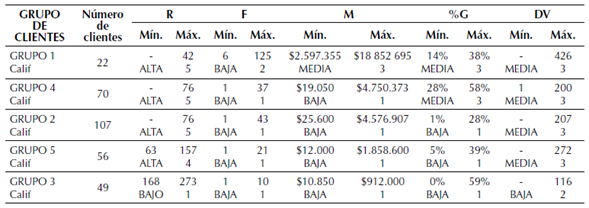
En este ranking, el grupo 1 concentra los clientes clave para la empresa, con el menor número de clientes, y mejores calificaciones. Tiene un solo atributo con calificación baja, sin embargo es de notar que es el único grupo que no tiene clientes que solo hayan realizado una compra en el periodo de estudio (frecuencia entre 6 y 125). El volumen de las compras de este grupo hace que la ganancia por cliente no sea tan alta (el máximo valor de la %G es de 38 %), pues al ser clientes mayoristas se ofrecen descuentos en el precio por volumen de compra.
El grupo 4, que es el segundo con más clientes asignados, tiene una frecuencia de compra baja y los montos de compra o monetario, también son bastante bajos. Pero tiene una ganancia por cliente bastante alta y es uno de los grupos con la mejor calificación en las variables R y DV. Al analizar con mayor detalle en la base de datos, los clientes de este grupo se encuentran en su mayoría en las afueras de la ciudad, compran periódicamente para abastecer sus negocios y son clientes que suelen pagar de contado. Los productos que suelen comprar son producidos por la empresa, por lo cual representan un alto margen de contribución para la misma, adicionalmente, al estar por fuera de la ciudad, la empresa no tiene tanta competencia con otros proveedores por estos clientes.
El grupo 2 tiene la mayor cantidad de clientes, y las variables muestran similitudes con el grupo 4. Pero los clientes de este grupo no tienen el potencial que se observa en los clientes del grupo 4, ya que la ganancia por cliente no es tan alta. Esto se debe a que compran casi todos los productos ofrecidos por la empresa, y algunos de estos productos tienen un margen por producto bajo, ya que son productos comercializados y no producidos por la empresa, pero son ofrecidos para que el cliente no utilice otro proveedor.
Los dos últimos dos grupos de clientes, 5 y 3, tienen las más bajas calificaciones. Aunque tienen clientes que generaron una ganancia para la empresa bastante alta, estos clientes no han comprado desde hace más de dos meses.
Aunque análisis adicionales de la información que se tiene de cada grupo pueden aportar más información a tener en cuenta en la toma de decisiones, los anteriores resultados, sirven como punto de partida, para la determinación y diseño de estrategias encaminadas a establecer relaciones más cercanas con los clientes, identificando dentro del conjunto clientes con los que actualmente se está trabajando, a aquellos que pueden ser claves para el crecimiento de la empresa.
CONCLUSIONES
El análisis RFM es ampliamente utilizado por su fácil compresión y aplicabilidad. Permite conocer el comportamiento de compra de los clientes según unos parámetros básicos, en busca de la identificación de aquellos clientes que aportan mayor valor a la empresa. Adicionalmente, este análisis se puede complementar con otras técnicas como técnicas de manipulación de datos, métodos gráficos de visualización, métodos de agrupación, junto con la introducción de nuevas variables, para obtener un análisis adaptado a las necesidades particulares de una empresa o industria.
Las bases de datos de una empresa pueden disponer de gran información sobre sus clientes, lo cual ofrece la posibilidad de nuevos parámetros de evaluación, que pueden integrarse al análisis del comportamiento de los clientes. Pero la integración de nuevos parámetros debe responder a preguntas que sean de interés para empresa y que los parámetros del análisis RFM no responden. En el caso de estudio, se definieron tres parámetros que se ajustaban a unos puntos de interés para de la empresa.
Antes de realizar la adición de nuevos parámetros al análisis RFM, es importante validar si estos realmente aportan un valor agregado al método tradicional, de lo contrario, puede resultar en análisis redundantes y errados de los clientes. En el caso de estudio, una de las variables propuestas, la G tiene una relación fuerte y positiva (variable dependiente) con la variable tradicional M (variable independiente), es decir que el comportamiento de la variable G se explica mediante el comportamiento de la variable M, razón por lo cual G se excluyó de las variables para realizar la segmentación. Esto no implica que no pueda ser utilizada en análisis posteriores de cada segmento.
Después de obtener la segmentación de los grupos, es importante realizar un análisis de los clientes que los componen, pues permite entender el comportamiento de las variables y así poder diseñar estrategias de marketing dirigidas a esos clientes, basadas en las características particulares de cada grupo.
Licencia
Esta licencia permite a otros remezclar, adaptar y desarrollar su trabajo incluso con fines comerciales, siempre que le den crédito y concedan licencias para sus nuevas creaciones bajo los mismos términos. Esta licencia a menudo se compara con las licencias de software libre y de código abierto “copyleft”. Todos los trabajos nuevos basados en el tuyo tendrán la misma licencia, por lo que cualquier derivado también permitirá el uso comercial. Esta es la licencia utilizada por Wikipedia y se recomienda para materiales que se beneficiarían al incorporar contenido de Wikipedia y proyectos con licencias similares.
