DOI:
https://doi.org/10.14483/22487638.22094Publicado:
27-10-2024Número:
Vol. 28 Núm. 79 (2024): Enero - MarzoSección:
InvestigaciónApplication of machine learning for predictions of consecutive dependent data of type {[(a, b)->c]->d}
Aplicación de machine learning para predicciones de datos dependientes consecutivos de tipo {[(a, b)->c]->d}
Palabras clave:
algorithms, datasets, decision trees, Python, prediction, scikit-learn, linear regression (en).Palabras clave:
algoritmos, datasets, árboles de decisión, Python, scikit-learn, regresión lineal (es).Descargas
Resumen (en)
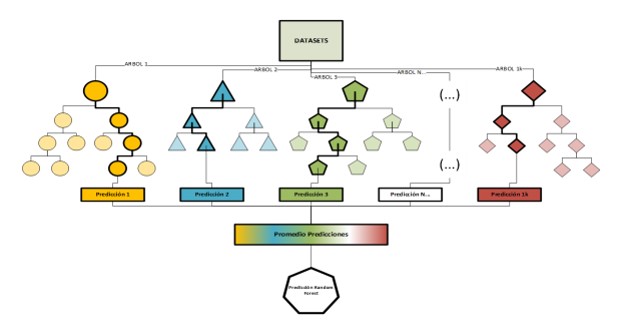
Objective: Machine learning techniques have emerged in response to the desire for automatic pattern detection withindatasets in fields such as statistics, mathematics, and data analytics. They allow for the extraction of relevant informationfrom datasets of significantly large volumes, providing the possibility of making predictions. This paper presents an application focused on decision trees, linear regression, and random forest regression algorithms to predict final data fromconsecutive dependent data of type {[(a, b) → c] → D}.
Methodology: The study adopts a quantitative research design, which takes as input datasets based on interval data. It utilizes a correlational research model by implementing Python and its Scikit-Learn library, which includes various algorithms for prediction. Specifically, we compare the application of decision trees, linear regression, and random forest regression on the same set of datasets, but with a characteristic of dependency between them.
Results: Upon application of the proposed model, it yields an estimated prediction score, which indicates the accuracy of the model concerning the data provided.
Conclusions: The application of a complex algorithm does not inherently guarantee a higher rate of accuracy. Conversely, configuring the model correctly, training multiple trees, or adjusting parameter values can significantly enhance the obtained results
Resumen (es)
Objetivo: Las técnicas de Machine Learning surgen como una respuesta al deseo de detectar automáticamente patrones en un conjunto de datos (datasets) en campos como la estadística, la matemática y la analítica de datos, permitiendo extraer información relevante de datasets de volúmenes significativamente grandes y realizar predicciones. Éste artículo presenta una aplicación enfocada en los algoritmos de árboles de decisión, regresión lineal y regresión aleatoria de tipo bosque para predecir un dato final a partir de datos dependientes consecutivos de tipo {[(a, b) → c] → D}.
Metodología: Se parte de un diseño de investigación cuantitativo, que toma como insumo unos datasets basados en datos de intervalo, establecidos en un modelo de investigación correlacional al aplicar Python y su librería Scikit-learn. Esta biblioteca incluye diferentes algoritmos que pueden ser utilizados para realizar predicciones. En este caso, se compara la aplicación de árboles de decisión, regresión lineal y regresión aleatoria de tipo bosque sobre un mismo grupo de datasets, pero que tienen una característica de dependencia entre ellos.
Resultados: Cuando se aplica el modelo propuesto, este genera un puntaje estimado de la predicción, el cual indica la precisión del modelo respecto a los datos entregados.
Conclusiones: La aplicación de un algoritmo complejo no garantiza un mayor índice de precisión; por el contrario, configurar de manera correcta el modelo, entrenando múltiples árboles o cambiando los valores de los parámetros mejora en gran medida los resultados obtenidos
Referencias
Bell, J. (2015). Machine learning Hands-On for Developers and Technical Professionals. Indiana: Wiley.
Breiman, L. (2001). Random Forest. California. University of California. https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf
Cardona, D., Rivera, M., González, J., & Cárdenas, E. (2014). Estimación y predicción con el modelo de regresión cúbica aplicado a un problema de salud. Ingenieria Solidaria, 10(17). https://doi.org/10.16925/in.v9i17.828
Díaz Martínez, Z., Fernández Menéndez, J., & Segovia Vargas, J. (2004). Sistemas de inducción de reglas y árboles de decisión aplicados a la predicción de insolvencias en empresas aseguradoras. Departamento de Economía Financiera y Contabilidad / Departamento de Organización de Empresas. Madrid: Universidad Complutense de Madrid. https://eprints.ucm.es/id/eprint/6833/
Feurer, M., & Hutter, F. (2019). Hyperparameter Optimization. In Automated Machine Learning (pp. 3-33). Springer. https://doi.org/10.1007/978-3-030-05318-5
García ruiz de León, M., Mira McWilliams, J. M., & Ahrazem Dfuf, I. (2018). Análisis de sensibilidad mediante Random Forest. Madrid: Universidad Politécnica de Madrid.
Hinestroza Ramírez, D., & Cárdenas, J. M. (2018). El Machine Learning a través de los tiempos, y los aportes a la humanidad. Pereira: Universidad Libre.
Maisueche Cuadrado, A. (2019). Utilización del Machine Learning en la industria 4.0. Valladolid: Universidad de Valladolid. Escuela de Ingenierías Industriales. http://uvadoc.uva.es/handle/10324/37908
Maisueche Cuadrado, A. (2019). Montero Granados, R. (2016). Modelos de regresión lineal múltiple. Granada, España: Universidad de Granada. http://www.ugr.es/~montero/matematicas/regresion_lineal.pdf
Segura Cardona, A. M. (2012). Aplicación de árboles de decisión en la salud pública (Implementation of decision trees in public health) (Aplicação de árvores de decisão em saúde pública). Revista CES salud pública, 3(1), 94-103. http://dx.doi.org/10.21615/2140
Song, Y.-Y.,& Ying, L. (2015). Decision tree methods: applications for classification and prediction. Shanghai Arch Psychiatry, 27(2), 130-135. https://doi.org/10.11919/j.issn.1002-0829.215044
Cómo citar
APA
ACM
ACS
ABNT
Chicago
Harvard
IEEE
MLA
Turabian
Vancouver
Descargar cita
Licencia
Derechos de autor 2024 Arnaldo Andres Gonzalez Gomez, Diego Alexander Quevedo Piratova, Jhon Uberney Londoño Villalba

Esta obra está bajo una licencia internacional Creative Commons Atribución-CompartirIgual 4.0.
Esta licencia permite a otros remezclar, adaptar y desarrollar su trabajo incluso con fines comerciales, siempre que le den crédito y concedan licencias para sus nuevas creaciones bajo los mismos términos. Esta licencia a menudo se compara con las licencias de software libre y de código abierto “copyleft”. Todos los trabajos nuevos basados en el tuyo tendrán la misma licencia, por lo que cualquier derivado también permitirá el uso comercial. Esta es la licencia utilizada por Wikipedia y se recomienda para materiales que se beneficiarían al incorporar contenido de Wikipedia y proyectos con licencias similares.
