
DOI:
https://doi.org/10.14483/udistrital.jour.tecnura.2015.2.a01Publicado:
01-04-2015Número:
Vol. 19 Núm. 44 (2015): Abril - JunioSección:
InvestigaciónCognición imitativa para un robot mediante una comunidad de replicadores neuro-meméticos
Imitative cognition for a robot through a community of neuro-memetic replicators (CNMR)
Descargas
Referencias
Aunger, R. (2004). El meme eléctrico: Una nueva teoría sobre cómo pensamos. Barcelona: Paidós.
Castillo, D.; Escobar, E.; Hermosillo, J., y Lara, B. (2013). Modelado de un sistema de neuronas espejo en un agente autónomo artificial. Nova Scientia, 5 (2)(10), 51-72.
Castillo, M. (2010). Control de motores de C.D. con aprendizaje por imitación basado en redes neuronales. México D.F.
Feng, L.; Ong, Y.-S.; Tan, A.-H., & Chen, X.S. (2011). Towards human-like social multi-agents with memetic automaton. En 2011 IEEE Congress on evolutionary computation (pp. 1092-1099).
Fernando, C., & Szathmáry, E. (2009). Chemical, neuronal and linguistic replicators. En: Towards an extended evolutionary synthesis (pp. 209-249). Cambridge: MIT Press.
Floreano, D.; Mitri, S.; Perez-Uribe, A., & Keller, L. (2008). Evolution of altruistic robots. En: Computational intelligence: Research frontiers (pp. 232-248). Springer-Verlag.
González, S. (2004). ¿Sociedades artificiales? Una introducción a la simulación social. Revista internacional de sociología (RIS), 62(39), 199-222.
Lahoz-Beltrá, R. (2004). Bioinformática: Simulación, vida artificial e inteligencia artificial. Madrid: Díaz de Santos.
Maldonado, C., y Gómez, N. (2010). Modelamiento y simulación de sistemas complejos. Documentos de investigación(66). Bogotá, Colombia: Universidad del Rosario.
Oudeyer, P.-Y., & Kaplan, F. (2007). Language evolution as a Darwinian process: Computational studies. Cognitive Processing, 8(1), 21-35.
Perozo, N. (2011). Modelado multiagente para sistemas emergentes y auto-organizados.
Sterpin, D. (2011). Perceptrón auto-supervisado: Una red neuronal artificial capaz de replicación memética. Revista Educación en Ingeniería(12), 90-101.
Cómo citar
APA
ACM
ACS
ABNT
Chicago
Harvard
IEEE
MLA
Turabian
Vancouver
Descargar cita
DOI: http://dx.doi.org/10.14483/udistrital.jour.tecnura.2015.2.a01
Cognición imitativa para un robot mediante una comunidad de replicadores neuro-meméticos
Imitative cognition for a robot through a community of neuro-memetic replicators (CNMR)
Dante Giovanni Sterpin Buitrago*
* Ingeniero electrónico, especialista en Docencia Universitaria, docente asociado en la Corporación Unificada Nacional de Educación Superior (CUN). Bogotá, Colombia. Contacto: dante_sterpin@cun.edu.co
Fecha de recepción: 11 de marzo de 2014 Fecha de aceptación: 19 de enero de 2015
Citation / Para citar este artículo: Sterpin Buitrago, D. G. (2015). Cognición imitativa para un robot mediante una comunidad de replicadores neuro-meméticos. Revista Tecnura, 19(44), 15-31. doi: http://dx.doi.org/10.14483/udistrital.jour.tecnura.2015.2.a01
Resumen
Como herramienta de inteligencia artificial, la computación memética emplea modelos de ciertos elementos cerebrales, llamados neuro-memes, hipotéticamente implicados en la simbolización, diseminación y evolución de las características culturales en las sociedades humanas. Con la finalidad de simular el gran potencial evolutivo de los neuro-memes, recientemente se presentó el Perceptrón auto-supervisado (SSP) como replicador neuro-memético artificial, cuya capacidad de aprendizaje imitativo fue verificada al controlar un robot muy sencillo. Con respecto a dicha capacidad se observó una deficiencia aprehensiva cuando el imitador solamente observa la conducta libremente evidenciada por el instructor. Al atender dicha deficiencia se encontró la incapacidad de imitar una conducta con ciertas características. Considerando que el SSP es un modelo orientado al desarrollo de sistemas colectivos, en este artículo se presenta un sistema multi-agente compuesto por varios SSP, con el cual se solucionaron dichas dificultades encontradas en un SSP individual.
Palabras clave: aprendizaje por imitación, mapa auto- organizado de Kohonen, neuro-meme, Perceptrón multicapa, red neuronal artificial, replicación neuro-memética, sistema multi-agente.
Abstract
Memetic computation, as an artificial intelligence tool, uses models of certain cerebral elements, called neuro-memes, hypothetically implicated in symbolization, dissemination and evolution of cultural characteristics in the human societies. In order to simulate the great evolutionary potential of neuro-memes, the Self-supervised perceptron (SSP) was recently presented as an artificial neuro- meme, and its imitative learning capability was verified through the control of a simple robot. Regarding that capability, it was observed an apprehensive deficiency when the imitator looks only the instructor's freely evidenced behavior. When attending that deficiency, it was found the incapability to imitate a behavior with certain characteristics. Whereas the SSP is a model oriented to develop collective systems, this paper presents an SSP-based multi-agent system, by which such difficulties found in a single SSP were solved.
Keywords: Artificial neural network, Imitative learning, Kohonen's self-organized map, Multi-agent system, Multilayer perceptron, Neuro-meme, Neuro- memetic replication.
Introducción
Una gran cantidad de sistemas naturales demuestran que es preferible resolver problemas en sociedad, y el intelecto humano ha logrado simular tecnológicamente esta estrategia mediante sistemas complejos como las redes neuronales, los algoritmos evolutivos y ciertas sociedades artificiales como los autómatas celulares, los enjambres inteligentes y los sistemas multi-agente. Dichas simulaciones permiten estudiar el comportamiento de los sistemas naturales y sociales de una manera más apropiada (Maldonado & Gómez, 2010), con la ventaja de evaluar estrategias de intervención social como con ningún otro método (González, 2004). Con la finalidad de simular las ventajas intelectuales de un sistema socio-cultural remotamente cercano al humano y, además, apoyar tecnológicamente el abordaje de sus respectivas problemáticas diarias, en la Corporación Unificada Nacional de Educación Superior (CUN) se ha proyectado una investigación fundamentada en la hipótesis del replicador neuronal (Fernando & Szathmáry, 2009) para lograr simular una sociedad con evolución cultural. Al respecto se inició diseñando un replicador neuro-memético artificial, el cual evidenció una dificultad aprehensiva cuya solución, presentada en este artículo, requirió emplear un conjunto de varios replicadores con capacidad de operar como un sistema multi-agente bastante sencillo.
Agentes y sistemas multi-agente
En el contexto de este artículo, un agente es un sistema computacional capaz de percibir cierta información de su entorno para ejecutar decisiones autónomamente, con la finalidad de lograr satisfactoriamente ciertos objetivos, ya sea en solitario o asociado con otros agentes, mediante la adquisición y utilización de conocimiento sobre las situaciones experimentadas. En cuanto a la capacidad de decisión existen dos arquitecturas básicas: re-activa y deliberativa. Los agentes empleados en este artículo son reactivos, pues son capaces de responder rápidamente ante la situación percibida sin necesitad de modelos explícitos del entorno, mientras que los deliberativos sí requieren dichos modelos para razonar sobre la mejor decisión en cada situación.
Cuando un problema implica considerar diversas instancias se requiere emplear varios agentes para enfrentarlo, pues intentar establecer una estrategia única podría resultar infructuoso. Para comprender y/o solucionar dichos problemas es preferible contar con una sociedad de agentes simples capaces de interaccionar a nivel micro, a partir de lo cual podrán emerger estructuras y/o comportamientos complejos a nivel macro, mediante la auto-organización de las partes del sistema como un todo. El modelamiento y la simulación mediante sistemas multi-agente está en la vanguardia investigativa, tanto en contextos tecnológicos (Perozo, 2011) como en contextos sociológicos (González, 2004), por su afinidad con la complejidad del mundo real.
Neuro-memes y evolución cultural
Así como la evolución biológica se basa en la selección, replicación y mutación de genes, la evolución cultural podría basarse en la selección, replicación y variación de neuro-memes, es decir, nodos neuronales capaces de replicar su patrón de activación estimulando a otros nodos para inducir en alguno de estos últimos un patrón semejante (Aunger, 2004). La existencia de dichos nodos es aún hipotética pero su conceptualización brinda un modelo explicativo para la emergencia de las diversas caracterizaciones culturales en las sociedades humanas, y además permite dilucidar el cerebro individual como un gran proceso de evolución cognitiva.
Con el propósito de simular completamente el enorme potencial del modelo evolutivo basado en neuro-memes, actualmente existen algunos modelos artificiales de replicación neuro-memética (Fernando & Szathmáry, 2009) y (Feng, Ong, Tan, & Chen, 2011), y también algunos modelos de la capacidad cerebral para aprender por imitación (Castillo, 2010) y (Castillo, Escobar, Hermosillo, & Lara, 2013), mediante la cual se propagan neuro-memes con eventuales modificaciones (Aunger, 2004). Comparado con dichos modelos el actualmente desarrollado en la CUN también emplea redes neuronales artificiales, pero está enfocado en demostrar a largo plazo el desarrollo autónomo de emoción y moralidad en una sociedad de agentes con evolución memética, individual y colectiva (Feng, Ong, Tan, & Chen, 2011), asumiendo la inexistencia de un Yo centralizado (González, 2004) y, procurando que su macro-universo social entrelace diversos micro-mundos individuales, para la auto-organización de una cultura artificial, lo cual sería un sistema evolutivo multi-agente con propiedades socio-culturales, elementales y emergentes, potencialmente útil en ingeniería y sociología.
Redes neuronales artificiales
Las neuronas artificiales son sistemas con un valor de conexión sináptica asociado a cada una de sus entradas, con lo cual regulan la estimulación de entrada y simbolizan el conocimiento de cómo activar su salida, a manera de respuesta, con respecto al estado entrante.
Perceptrón multicapa (MLP)
Una de las interconexiones neuronales artificiales más utilizadas consiste en organizar neuronas artificiales en una capa perceptora, una o varias capas intermedias y una capa efectora, de tal modo que mediante un proceso de propagación informática se obtienen las activaciones con las cuales el MLP opera como un agente reactivo frente a la situación percibida. El entrenamiento de esta red neuronal le permite desarrollar patrones reactivos acordes con el comportamiento requerido por un usuario, para lo cual el diseñador especifica un conjunto de ejemplos senso-motores con los cuales se ajustan las conexiones sinápticas, en función de obtener los niveles de activación motriz requeridos para el respectivo caso sensorial en cada ejemplo.
Dicha composición de ejemplos es para un MLP como el Super-Yo es para el Yo (Lahoz-Beltrá, 2004), y por tanto puede interpretarse como una especie de “supervisor moral” para el MLP, pues de esta manera se le instituyen las normas de un deber-hacer que aprende a evidenciar como conducta “moralmente correcta”, al resultar operativamente atraído hacia dicha normativa. Este símil es bastante peculiar en el desarrollo del presente artículo, pero la ética implicada está fuera de su alcance. Al entrenamiento del MLP se le conoce como aprendizaje supervisado y su efectividad depende de la calidad con que se especifique el patrón moral, es decir, el conjunto de ejemplos senso-motores del deber-hacer. Durante este proceso de aprendizaje se emplean dos medidas de error: uno de entrenamiento directo y otro de generalización; el primero utiliza un porcentaje alto del patrón moral para evaluar cómo está reaccionando el MLP, con respecto a la forma como debe-reaccionar, mientras el segundo utiliza el resto de la moral para testear el comportamiento del MLP en situaciones que no se le enseñan directamente.
Mapa auto-organizado (SOM)
Este modelo neuronal está conformado por una capa de neuronas sensoriales interconectadas sinápticamente con una estructura 2D o 3D de neuronas cognitivas, y es capaz de asimilar e identificar patrones de semejanza presentes en sus percepciones. El entrenamiento del SOM no requiere patrones predefinidos por el diseñador, por lo cual dicho proceso se conoce como aprendizaje no-supervisado, donde la modificación sináptica depende de ciertos factores cuyo valor disminuye con el tiempo, razón por la cual el SOM está inicialmente “abierto” a los cambios cognitivos y, conforme avanza el tiempo, pierde flexibilidad sináptica hasta “cerrarse” tras suceder cierta cantidad predefinida de iteraciones.
Perceptrón auto-supervisado (SSP)
Al modelo de replicación neuro-memética recientemente diseñado en el programa de ingeniería electrónica de la CUN se le denominó Perceptrón auto-supervisado, pues hibrida un Perceptrón multicapa (MLP) y un Mapa auto-organizado (SOM). Su funcionamiento combina el aprendizaje no-supervisado propio del SOM y el aprendizaje supervisado propio del MLP, con la finalidad de utilizar el conocimiento asimilado por el SOM para auto-entrenar la conducta del MLP y así, el SSP es también un neuro-agente con aprendizaje imitativo, pues el SOM asimila los patrones de una conducta instruida y el MLP los habitúa (Sterpin, 2011).
La capacidad aprehensiva del SSP fue verificada mediante un robot virtual con la necesidad de imitar dos tareas básicas por separado –evadir obstáculos predominantemente por la izquierda (EOPI) y seguir contornos a cierta distancia por la derecha (SCD), en un ambiente continuo de tipo laberinto. Tras dicha verificación se detalló cierta deficiencia en el conocimiento adquirido por el imitador y al solucionarla se encontró la imposibilidad de imitar cierto tipo de comportamiento instruido. A continuación se describirán estos problemas aprehensivos en un SSP individual y la forma como se logró solucionarlos desarrollando un modelo colectivo con varios SSP.
Metodología
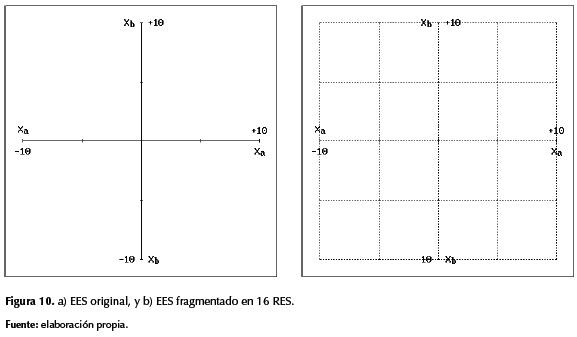
El robot empleado simula dos sensores fronto-laterales {A ; B}, cuya información numérica puede variar independientemente entre [-10 ; +10] en correspondencia con la distancia entre el robot y los obstáculos. De esta manera las posibles situaciones sensoriales del robot pueden referenciarse mediante coordenadas (xa ; xb) en el plano: {Xa: [-10 ; +10]} x {Xb: [-10 ; +10]}, denominado espacio de eventualidades sensoriales (EES). Adicionalmente, el robot simula la tracción diferencial central de dos motores {C ; D}, cuya velocidad puede variar independientemente en el rango [-10 ; +10], por lo cual las posibles actuaciones del robot pueden referenciarse mediante coordenadas (yc ; yd) en el plano: {Yc: [-10 ; +10]} x {Yd: [-10 ; +10]}, denominado espacio de manifestaciones motrices (EMM), mientras las posibles actuaciones definidas en el patrón moral pueden referenciarse mediante coordenadas (tc ; td) en el plano: {Tc: [-10 ; +10]} x {Td: [-10 ; +10]}, denominado espacio de necesidades motrices (ENM).
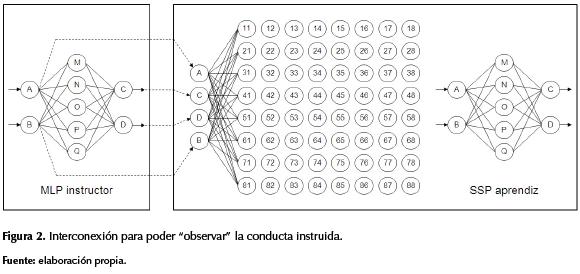
En la figura 1 se detallan el robot y dos de los laberintos empleados en los experimentos, en donde se demostró que al ser controlado mediante SSP logra imitar las tareas EOPI y SCD. En la figura 2 se muestra el MLP empleado tanto en el instructor como en el aprendiz, el SOM de este último, y la interconexión para el proceso de enseñanza/aprendizaje entre ambos. Dicho vínculo permite que las neuronas sensoriales {A ; B ; C ; D} del SOM aprendiz dispongan de la información presente tanto en las neuronas sensoriales {A ; B} como en las efectoras {C ; D} del MLP instructor, con lo cual el aprendiz puede “observar” exactamente las acciones ejecutadas por el instructor en cada una de las situaciones sensorialmente experimentadas por este último.
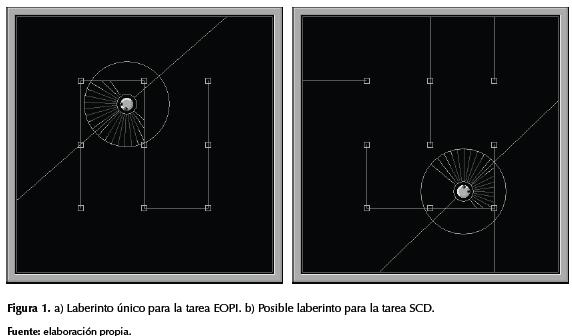
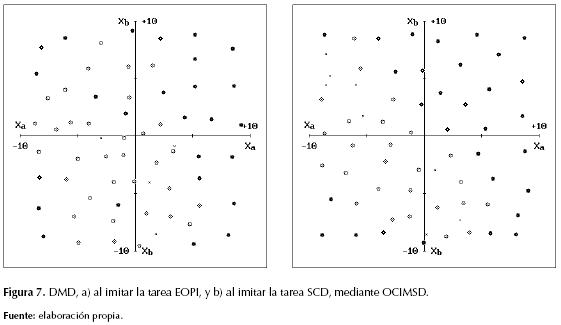
El conjunto de casos (xa ; xb) del patrón moral corresponde a su dominio moral en el EES, y en la figura 3 se detallan los 64 casos, uniformemente distribuidos, del dominio moral propio de cada instructor. La figura 4 permite detallar el dominio moral desarrollado (DMD) por el aprendiz en cada tarea, donde cierta cantidad de muestras situacionales conformaron un perfil irregular en el EES. En cada una de estas tareas la forma particular de dicha irregularidad circunscribe las situaciones asimiladas por el aprendiz al “observar” la conducta libremente evidenciada por el instructor (OCLEI), mientras este último se movía en su respectivo laberinto.

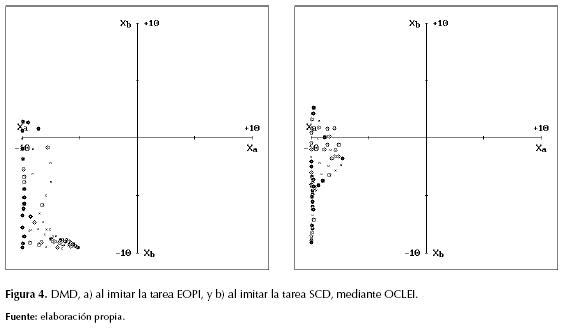
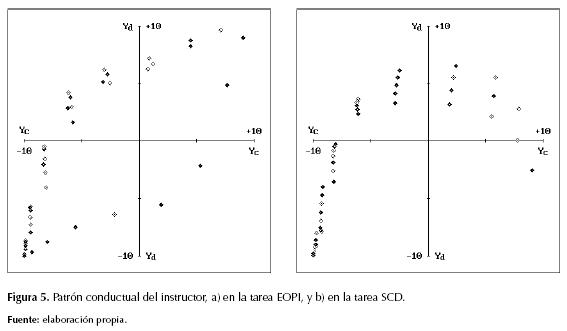
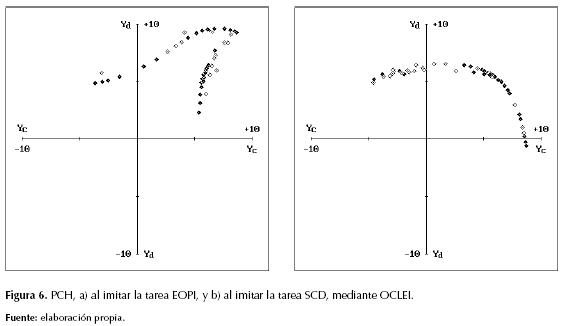
Dichas visualizaciones permitieron notar una marcada deficiencia cognitiva entre instructor y aprendiz, pues este último quedó desprovisto de auto-supervisión moral en gran parte del EES y, por ende, su conducta en las situaciones moralmente desconocidas fue “intuida” a partir del escaso patrón moral asimilado (PMA) por el aprendiz en cada tarea. El conjunto de actuaciones (yc ; yd) del MLP, para los casos (xa ; xb) del patrón moral, corresponde a su patrón conductual en el EMM, y al comparar las figuras 5a y 6a, así como al comparar las figuras 5b y 6b, puede detallarse la diferencia entre cada conducta instruida y su respectivo patrón conductual habituado (PCH). Frente a dicha deficiencia el problema atendido consistió en: ¿cómo dotar a un sistema basado en SSP con la capacidad de imitar completamente la conducta de un MLP instructor?
Ampliación del dominio moral
A pesar de dicha diferencia cada aprendiz logró comportarse como su respectivo instructor, pero con la finalidad de lograr un DMD más amplio se decidió modificar la dinámica de enseñanza/aprendizaje así: primero se obvió la necesidad de “observar” la socialización conductual del instructor, pues se pretende considerar que juntos, tanto instructor como aprendiz, conforman un único sistema neuronal para controlar un robot individual, con el propósito de simular la replicación neuro-memética en el interior de un cerebro humano individual (Aunger, 2004). Acto seguido se implementó un procedimiento mediante el cual el aprendiz pudiese “observar” el comportamiento del instructor en múltiples situaciones dispersas (OCIMSD), para lo cual se generó una secuencia aleatoria de las posibles situaciones sensoriales: {Xa: Random[-10 ; +10], Xb: Random[-10 ; +10]}, con el fin de estimular el MLP instructor y, al obtener de este los respectivos valores {yc ; yd}, mostrarle al SOM del SSP una mayor diversidad de ejemplos sobre la conducta instruida.
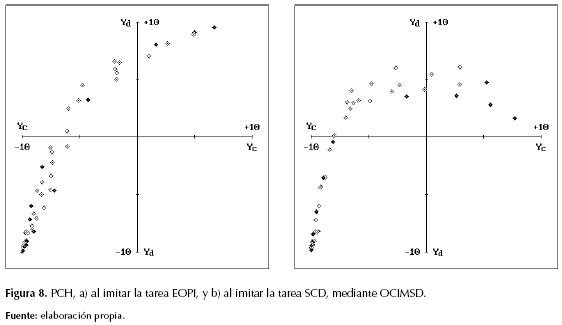
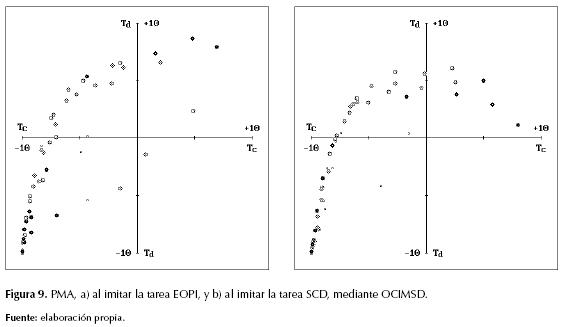
En las figuras 7 y 8 pueden detallarse, respectivamente, el DMD y el PCH del aprendiz en cada tarea. Efectivamente ambos aprendices asimilaron mayor conocimiento moral y el aprendiz de la tarea SCD logró imitarla exitosamente; sin embargo, el aprendiz de la tarea EOPI no logró comportarse como el instructor, lo cual se evidencia mediante la motricidad faltante entre las figuras 5a y 8a. Esto se debió a la baja frecuencia de ciertos patrones propios de la tarea EOPI, con respecto al carácter estadístico de la función de enlace [Pμ] entre SOM y MLP en el SSP, pues tras el “cierre” del SOM las neuronas cognitivas cuya frecuencia de estimulación supera cierta frecuencia crítica [fc] son las únicas cuyo conocimiento sináptico influye directamente en el entrenamiento del MLP (Sterpin, 2011). Como dichos patrones son bastante esporádicos no logran superar la frecuencia [fc], y la función [Pμ] los designa como patrones de generalización muy difíciles para el MLP, lo cual se evidencia al comparar las figuras 8a y 9a, pues esta última muestra las debidas actuaciones (tc ; td) del respectivo PMA en el ENM.
En las gráficas de los patrones morales, tanto del MLP instructor como del SSP aprendiz, los puntos circulares referencian coordenadas (xa ; xb) en el EES o coordenadas (tc ; td) en el ENM. En las gráficas de los patrones conductuales del MLP, bien sea instructor o aprendiz, los puntos romboidales referencian coordenadas (yc ; yd) en el EMM. El relleno en dichos puntos permite diferenciar los patrones utilizados para entrenar del respectivo MLP, pues los puntos con-relleno identifican los patrones designados para el entrenamiento directo, mientras los puntos sin-relleno identifican a los patrones empleados para evaluar la capacidad de generalización. Adicionalmente, los puntos con forma de cruz en los patrones morales del SSP aprendiz identifican ejemplos completamente excluidos por la función de enlace [Pμ] entre SOM y MLP en el SSP (Sterpin, 2011).
Considerando la dificultad observada al imitar la tarea EOPI, procurando que el SSP aprendiz desarrollara un amplio dominio moral mediante OCIMSD, el problema por resolver se modificó así: ¿cómo dotar a un sistema basado en SSP con la capacidad de imitar completamente la conducta de un MLP instructor, aun cuando dicha conducta incluya patrones de baja frecuencia estadística?
Desarrollo del modelo colectivo
Considerando la gran ventaja de resolver problemas globalmente mediante la cooperación entre agentes capaces de solucionar localmente fragmentos del problema, se decidió fragmentar el aprendizaje imitativo basado en SSP, empleando un conjunto de dichos replicadores con el fin de imitar una conducta mediante varios neuro-agentes. En función de dicha idea se desarrolló un sistema multi-agente capacitado para controlar el robot en cuestión, asignándole a cada SSP incorporado la responsabilidad de asimilar y habituar la conducta instruida en alguna región del espacio sensorial (RES), delimitando dichas regiones mediante planos comprendidos en el EES, así: 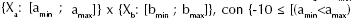 y
y 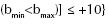 . En la figura 10b se detalla una posible forma de especificar dicha fragmentación.
. En la figura 10b se detalla una posible forma de especificar dicha fragmentación.
Para esto se asumió que el SSP es un neuro-agente con suficiente autonomía, pues aparte de percibir su situación y reaccionar al respecto, empleando su propio conocimiento sináptico, es también capaz de asimilar su propio patrón moral y auto-supervisar su propio comportamiento según cierto requerimiento conductual, en este caso instruido mediante el comportamiento de otro agente (Sterpin, 2011). Además, se asumió que el conjunto de los SSP podría lograr la emergencia de cierta cooperación multi-agente, con la cual pudiesen superarse las limitaciones aprehensivas de un solo SSP, al fragmentar el EES para distribuirles la información sensorial del robot y permitiéndole a cada SSP especializarse localmente en su respectiva RES.
La fragmentación del EES se efectuó cuadriculándolo –tal como en la figura 10b, y restringiéndole la OCIMSD al SSP localizado en cada RES, generando secuencias aleatorias según sus posibles situaciones: {Xa: Random[amin; amax], Xb: Random[bmin; bmax]}, para obtener del MLP instructor los respectivos valores {yc ; yd}. Primero se entrenaron los 16 SOM, empleando: 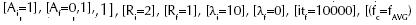 para
para 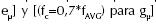 como parámetros del aprendizaje imitativo (Sterpin, 2011), y tras un promedio de 50000 iteraciones de entrenamiento para los 16 MLP se evaluó su capacidad cooperativa, confiriéndole el control motor del robot al SSP especializado en cada posible situación que aquél percibiera en el laberinto.
como parámetros del aprendizaje imitativo (Sterpin, 2011), y tras un promedio de 50000 iteraciones de entrenamiento para los 16 MLP se evaluó su capacidad cooperativa, confiriéndole el control motor del robot al SSP especializado en cada posible situación que aquél percibiera en el laberinto.
Resultados
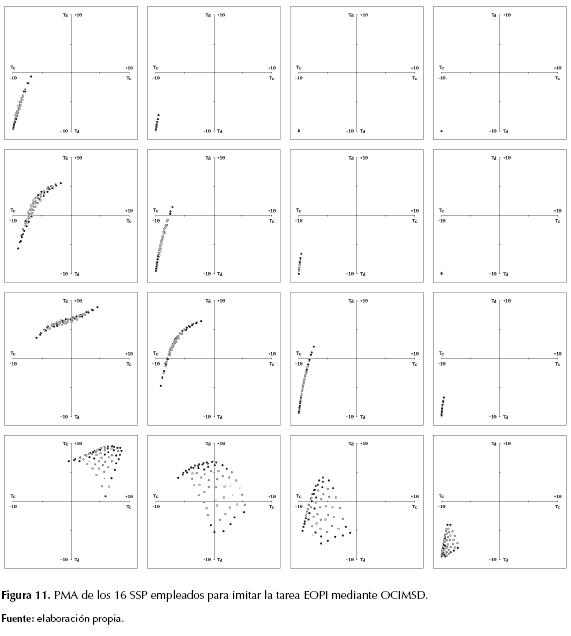
En efecto, la conducta del robot controlado mediante el conjunto de 16 SSP permitió evidenciar la imitación completa de las tareas EOPI y SCD. La figura 11 detalla el PMA del SSP empleado en cada una de las 16 RES al imitar la tarea EOPI, mientras la figura 12 detalla los respectivos PMA al imitar la tarea SCD. La figura 13a detalla en una gráfica única el DMD en cada una de las 16 RES al imitar la tarea EOPI, mientras la figura 13b detalla el respectivo DMD total al imitar la tarea SCD.
Recordando que la incapacidad de un SSP individual para imitar completamente la tarea EOPI se evidenció mediante la motricidad faltante entre las figuras 5a y 8a, las cuatro gráficas inferiores de la figura 11 permiten verificar que en la RES: {Xa: [-10 ; +10]} x {Xb: [-10 ; -5]} están los cuatro replicado-res debido a los cuales resultó posible asimilar los patrones de baja frecuencia estadística –propios de dicha tarea, pues los puntos con-relleno en sus respectivos PMA indican que dichos patrones fueron escogidos por la función [Pμ] para auto-entrenar directamente los cuatro MLP implicados.
Al entrenar uniformemente los 16 replicadores sucedió que algunos aprendían más lentamente, debido a la dificultad con la cual el MLP habituaba operativamente los deberes morales asimilados por su respectivo SOM. Con respecto a dicha disparidad se distribuyó una probabilidad según la medida individual del error cuadrático medio (ECM), con lo cual se proporcionaron prioridades en la medida en que el aprendizaje se dificultaba para ciertos SSP con respecto a los demás. Mediante la distribución de dichas prioridades el ECM total del conjunto de replicadores disminuyó más rápidamente.
Discusión
Considerando que cada uno de los 16 SSP detallados antes es un neuro-agente con la capacidad de especializarse autónomamente en cierta porción del problema, y considerando que en conjunto le dan solución al problema global, dicha comunidad de replicadores neuro-meméticos (CNMR) en efecto funciona como un sistema multi-agente cuyo carácter cooperativo, demostrado mediante la cohesión conductual al controlar el robot virtual, no requirió emplear comunicación directa entre los neuro-agentes, ni interacciones indirectas a través del entorno, pues se obtuvo solamente con la interacción didáctica entre el instructor y los aprendices. Debido a esto, la cohesión conductual propia del MLP instructor fue heredada por la CNMR. Además, al estimar el SSP como un Yo artificial, con su propio Super-Yo adquirido, podría estimarse a la CNMR como una asociación descentralizada de varios Yos artificiales, donde cada uno es capaz de asumir el control en situaciones para las cuales es particularmente experto.
Sobre cierta conformación celular
Con respecto a la figura 10, vale la pena mencionar que no es obligatorio fragmentar el EES en partes iguales ni de forma estrictamente cuadriculada; sin embargo, y con independencia de la manera como se fragmente, al distribuir los SSP para conformar la respectiva CNMR se obtiene una estructura celular en donde cada célula corresponde a un SSP como neuro-agente autónomo, y en donde pueden aplicarse interacciones a nivel de vecindario celular. Este sistema multi-agente es muy simple y, por tanto, puede considerársele como una micro-sociedad potencialmente útil en una macro-sociedad artificial, donde lo complejo pueda emerger a manera de estructuras auto-organizadas basadas en procesos simples (González, 2004) y (Perozo, 2011), lo cual tiene grandes alcances en sistemas evolutivos artificiales, como se ha visto con respecto al lenguaje (Oudeyer & Kaplan, 2007), y con respecto al altruismo cooperativo (Floreano, Mitri, Perez-Uribe, & Keller, 2008).
Sobre cómo minimizar la complejidad temporal
Una desventaja de la CNMR es el elevado consumo de tiempo con respecto a la duración del aprendizaje imitativo en conjunto, para lo cual se probaron dos alternativas de minimización: en una se redujo la cantidad de RES necesarias para imitar completamente la tarea EOPI, y en la otra se redujo la cantidad de MLP entrenados al compartir el conocimiento asimilado por los SOM en cierto vecindario celular. A continuación se detalla cada una de ellas.
Minimización al optimizar la fragmentación del EES
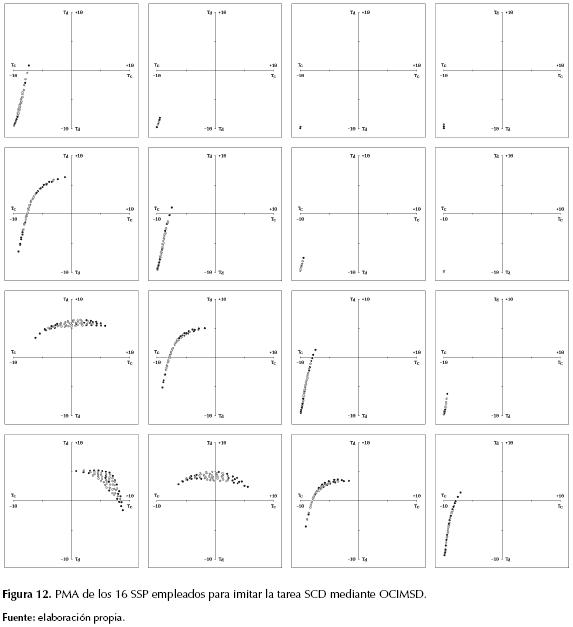
Para esta forma de reducir la complejidad temporal se determinó emplear un único SSP como remplazo de varios, por lo cual se sustituyeron los 12 replicadores originalmente empleados en la RES: {Xa: [-10 ; +10]} x {Xb: [-5 ; +10]}, con un solo SSP cuyo PMA logra sintetizar los PMA de dichos replicadores, lo cual puede detallarse al comparar la figura 14b con las 12 gráficas superiores de la figura 11.
La efectividad de dicho remplazo se verificó al notar que, con solo cinco SSP, la nueva CNMR logró imitar completamente la tarea EOPI, manteniendo un amplio DMD, tal como puede detallarse en la figura 14a, en comparación con la figura 13a.

Minimización al compartir la moral entre vecinos
A diferencia de los experimentos antes mencionados, –en donde cada MLP fue entrenado de modo individualista con la moral de su respectivo SOM, en esta segunda forma de reducir la complejidad temporal se permitió que los SOM, en cierto vecindario celular, compartieran su conocimiento de auto-supervisión moral para entrenar un único MLP con varios PMA. En este caso se emplearon los 16 PMA de la figura 11 para entrenar solo cuatro MLP, logrando imitar la tarea EOPI completamente, sin reducir el DMD de la CNMR compuesta por 16 SSP, y con una reducción de la complejidad temporal aún más notoria si originalmente los 16 replicadores habían sido moralmente supervisados por sus respectivos vecinos. En la figura 15 se detallan el DMD y el PCH correspondiente a uno de los cuatro SSP en la CNMR de este experimento.
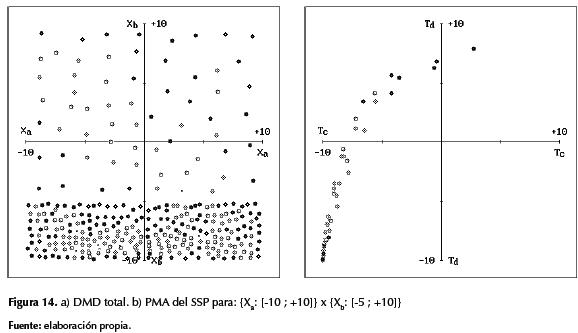
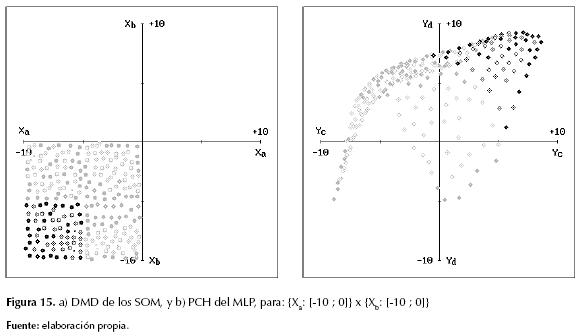
En las gráficas de esta última figura debe considerarse que los puntos grises corresponden a las RES vecinas de cierta RES central, la cual se caracteriza con puntos negros, y vale la pena mencionar además que la forma y relleno de dichos puntos mantiene el mismo significado detallado previamente.
Conclusión
El aporte específico del presente trabajo es un modelo computacional de aprendizaje imitativo comunitario, basado en la replicación neuro-memética de varios SSP, al cual se le denominó Comunidad de replicadores neuro-meméticos (CNMR). Los resultados experimentales permiten afirmar que la CNMR es un sistema multi-agente mediante el cual se logró mejorar la capacidad aprehensiva de un solo SSP, pues mediante la asociación descentralizada de varios SSP logró imitar completamente una conducta con patrones de baja frecuencia estadística. Además, dicho modelo permite estimar agentes individuales como micro-sociedades de varios Yos artificiales.
Las optimizaciones para reducir su complejidad temporal resultaron satisfactorias; sin embargo, fueron mediadas por el diseñador y en trabajos subsiguientes podrían obtenerse como producto emergente de un sistema evolutivo basado en la selección competitiva, replicación e innovación neuro-memética de varias CNMR, con el propósito de otorgarle autonomía al evaluar y mejorar diversas formas de distribuirle el problema a cierta cantidad de replicadores neuro-meméticos. Además, dicho modelo podría aplicarse en situaciones donde la cooperación debiese emerger mediante interacciones adicionales al vínculo entre instructor y aprendiz, y más allá del simple acceso público al conocimiento individualmente adquirido.
Financiación
Los resultados presentados en este artículo se obtuvieron durante el desarrollo de la segunda fase del Proyecto Medusa, lo cual fue avalado y financiado por la Corporación Unificada Nacional de Educación Superior (CUN) entre 2012 y 2013.
Referencias
Aunger, R. (2004). El meme eléctrico: Una nueva teoría sobre cómo pensamos. Barcelona: Paidós.
Castillo, D.; Escobar, E.; Hermosillo, J., y Lara, B. (2013). Modelado de un sistema de neuronas espejo en un agente autónomo artificial. Nova Scientia, 5 (2) (10), 51-72.
Castillo, M. (2010). Control de motores de C.D. con aprendizaje por imitación basado en redes neuronales. México D.F.
Feng, L.; Ong, Y.-S.; Tan, A.-H., & Chen, X.-S. (2011). Towards human-like social multi-agents with memetic automaton. En 2011 IEEE Congress on evolutionary computation (pp. 1092-1099).
Fernando, C., & Szathmáry, E. (2009). Chemical, neuronal and linguistic replicators. En: Towards an extended evolutionary synthesis (pp. 209-249). Cambridge: MIT Press.
Floreano, D.; Mitri, S.; Perez-Uribe, A., & Keller, L. (2008). Evolution of altruistic robots. En: Computational intelligence: Research frontiers (pp. 232-248). Springer-Verlag.
González, S. (2004). ¿Sociedades artificiales? Una introducción a la simulación social. Revista internacional de sociología (RIS), 62(39), 199-222.
Lahoz-Beltrá, R. (2004). Bioinformática: Simulación, vida artificial e inteligencia artificial. Madrid: Díaz de Santos.
Maldonado, C., y Gómez, N. (2010). Modelamiento y simulación de sistemas complejos. Documentos de investigación(66). Bogotá, Colombia: Universidad del Rosario.
Oudeyer, P.-Y., & Kaplan, F. (2007). Language evolution as a Darwinian process: Computational studies. Cognitive Processing, 8(1), 21-35.
Perozo, N. (2011). Modelado multiagente para sistemas emergentes y auto-organizados.
Sterpin, D. (2011). Perceptrón auto-supervisado: Una red neuronal artificial capaz de replicación memética. Revista Educación en Ingeniería(12), 90-101.
Licencia
Esta licencia permite a otros remezclar, adaptar y desarrollar su trabajo incluso con fines comerciales, siempre que le den crédito y concedan licencias para sus nuevas creaciones bajo los mismos términos. Esta licencia a menudo se compara con las licencias de software libre y de código abierto “copyleft”. Todos los trabajos nuevos basados en el tuyo tendrán la misma licencia, por lo que cualquier derivado también permitirá el uso comercial. Esta es la licencia utilizada por Wikipedia y se recomienda para materiales que se beneficiarían al incorporar contenido de Wikipedia y proyectos con licencias similares.
