DOI:
https://doi.org/10.14483/udistrital.jour.reving.2013.1.a02Publicado:
2013-06-30Número:
Vol. 18 Núm. 1 (2013): Enero - JunioSección:
ArtículosExtensión de taxonomía y tratamiento de valores faltantes sobre un repositorio de incidentes de seguridad informática
Taxonomy extension and missing-values treatment over an informatics-security incident repository
Palabras clave:
categorical data, data mining, data pre-processing, security incident, repository, taxonomy. (en).Palabras clave:
datos categóricos, incidente de seguridad, minería de datos, pre-procesamiento de datos, repositorio, taxonomía. (es).Descargas
Referencias
John D. Howard, Thomas A. Longstaff. “A Common Language for Computer Security Incidents”. Sandia National Laboratories, Octubre 1998.
Carlos Carvajal, Diego Bayona, Análisis de Incidentes de Seguridad Informática Mediante Minería de Datos, para Modelado de Comporta-miento y Reconocimiento de Patrones, Tesis para acceder al título de Ingeniería de Sistemas de la Universidad Francisco José de Caldas, Bogotá, Colombia, 2012.
Web Application Security Consortium. “Web Hacking Incident DataBase”, http://projects.webappsec.org/w/page/13246995/Web-Hacking-Incident-Database
Privacy Rights ClearingHouse, “Chronology of Data Breaches”. http://www.privacyrights.org/data-breach
COL-CSIRT, Grupo de Investigación Universidad Distrital. http://gemini.udistrital.edu.co/comunidad/grupos/arquisoft/colcsirt/
CERT Brasil. “Centro de estudios de respuesta y tratamiento de incidentes de Seguridad de Brasil”. http://www.cert.br/
INTECO España – Instituto Nacional del Tecnologías de la Comunicación. Centro de respuesta a incidentes de seguridad TIC. http://cert.inteco.es
"Hackers hit Tunisian websites" ALJAZEERA, Red de Noticias, 3 de Junio 2011, http://www.aljazeera.com/news/africa/2011/01/201113111059792596.html
"Secunia recovers from DNS redirection hack" The Register, Publicación Online de Tecnología, 26 de Noviembre de 2010. http://www.theregister.co.uk/2010/11/26/secunia_back_from_dns_hack/
"Cops: Hacker Posted Stolen X-rated Pics on Facebook" PCWorld, Magazín de Computación, 2 de Noviembre de 2010. http://www.pcworld.com/businesscenter/article/209584/cops_hacker_posted_stolen_xrated_pics_on_facebook.html
COMPUTERWORLD, Magazín de Computación. http://www.computerworld.com/s/article/9149218/Bank_sues_victim_of_800_000_cybertheft
"Bank sues victim of $800,000 cybertheft" The Washington Post, Periódico de la ciudad de Washington, 26 de Enero de 2010. http://www.washingtonpost.com/wp-dyn/content/article/2010/03/18/AR2010031805464.html
"Hackers Take Over BP Twitter Feed" FOX NEWS, Red de noticias, 27 de Mayo de 2010. http://www.foxnews.com/tech/2010/05/27/hackers-bp-twitter-feed/
Jiawei Han, Micheline Kamber. “Data Mining: Concepts and Techniques”. Morgan Kaufmann Publishers 2000, Capitulo 3 "Data Preprocesing".
Roderick J. A. little, Donald B. Rubin. "Statistical Analysis with Missing Data". Capitulo 6 "Theory of Inference Based on the Likelih-ood Function".
Dorian Pyle. "Data Preparation for Data Mining". Capitulo 8 "Replacing Missing and Empty Values". http://www.temida.si/~bojan/MPS/materials/Data_preparation_for_data_mining.pdf
Jaisheel Mistry. "Estimating Missing Data and Determining the Confidence of the Estimate Data"Seventh International Conference on Machine Learning and Applications, 2008.
Ludmila Himmelspach. "Clustering Approaches for Data with Missing Values: Comparison and Evaluation",Institute of Computer Science Heinrich-Heine-Universität Düsseldorf, 2010.
Jiawei Han, Micheline Kamber. “Data Mining: Concepts and Techniques”. Morgan Kaufmann Publishers 2000, Capitulo 8 "Cluster Analy-sis".
Xiao-Bai Li . “A Bayesian Approach for Estimating and Replacing Missing Categorical Data”. ACM Journal of Data and Information Quality, Vol. 1, No. 1, Article 3, Junio 2009.
“ABC de la Circular Externa 052 DE 2007", Comunicado de Prensa, Superintendencia Financiera de Colombia, Noviembre 7 de 2007. http://www.superfinanciera.gov.co/
“ISO/IEC 27001 : 2005 Tecnología de la Información- Técnicas de seguridad- Sistemas de gestión de seguridad- Requerimientos ”. Están-dar Internacional, Octubre 2005. http://www.iso.org/iso/home.html
Cómo citar
APA
ACM
ACS
ABNT
Chicago
Harvard
IEEE
MLA
Turabian
Vancouver
Descargar cita
EXTENSIÓN DE TAXONOMÍA Y TRATAMIENTO DE VALORES FALTANTES SOBRE UN REPOSITORIO DE INCIDENTES DE SEGURIDAD INFORMÁTICA
TAXONOMY EXTENSION AND MISSING-VALUES TREATMENT OVER AN INFORMATICS-SECURITY INCIDENT REPOSITORY
Carlos Javier Carvajal Montealegre, Universidad Distrital. Bogotá, Colombia. Ing.carlosj@gmail.com
Diego Nicolás Bayona, Universidad Distrital. Bogotá, Colombia. Nicolas.bayona@gmail.com
Zulima Ortiz Bayona, Universidad Distrital. Bogotá, Colombia. zortiz@udistrital.edu.co
Recibido: 18/01/2013 - Aceptado: 14/06/2013
RESUMEN
En este artículo se detalla el proceso de estimación de datos faltantes mediante el teorema de Bayes, sobre un repositorio de incidentes de seguridad informática compuesto por datos de tipo categórico. Así mismo, se hace uso de una taxon omía, ampliada y redefinida para acoplarse a los incidentes encontrados.
Palabras clave: Datos categóricos, incidente de seguridad, minería de datos, pre-procesamiento de datos, repositorio, taxonomía.
ABSTRACT
This paper describes the missing-values estimation process through the Bayes theorem acting over an information security incident repository composed by categorical data. Additionally, an augmented taxonomy is defined to account for the identified incidents.
Key words: Categorical data, data mining, data pre-processing, security incident, repository, taxonomy.
1. INTRODUCCIÓN
Un incidente de seguridad se define como la agrupación de una o más acciones llevadas a cabo por un atacante para lograr un resultado no autorizado en un sistema informático. Pueden ser distinguidas de otro grupo de acciones por las características de quien ataca, como ataca, qué objetivos tiene, quien fue el blanco del ataque y cuando se ejecutaron dichas acciones.
Este tipo de incidentes son reportados y dichos reportes son comúnmente accesibles desde Internet; en algunas ocasiones los reportes mantienen una estructura diferenciando algunas características previamente definidas, en otros casos son descripciones vagas y subjetivas. El conjunto de incidentes debe asegurar que sus elementos puedan ser descritos mediante las mismas características, para lo cual es necesario contar con un estándar descriptivo o taxonomía. Lo anterior con el fin de permitir análisis de minería de datos.
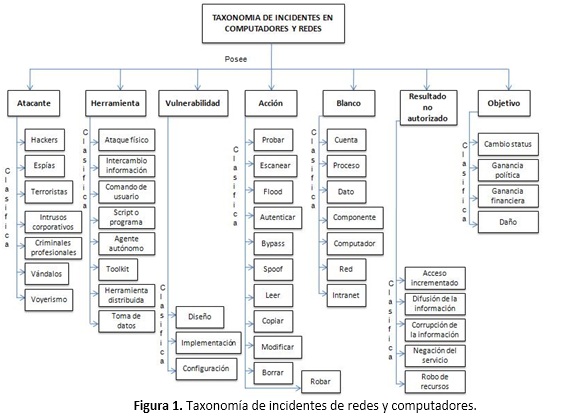
La taxonomía propuesta por el instituto Sandia en el artículo “A Common Language for Computer Security Incidents” [1], permite identificar y caracterizar estos incidentes, los campos de la taxonomía se observan en la Figura 1.
Durante la recopilación de incidentes de seguridad realizada como parte de la investigación en el proyecto de grado "Análisis de Incidentes de Seguridad Informática Mediante Minería de Datos, para Modelado de Comportamiento y Reconocimiento de Patrones" [2] se observó la necesidad de ajustar la taxonomía antes descrita. De la misma forma, fue necesario considerar el problema de valores faltantes (missing values), en la construcción del repositorio, debido a que algunos valores de los incidentes no pueden ser capturados. Los resultados obtenidos en dicho proyecto se reportan en este artículo.
La organización del artículo es la siguiente: en la Sección 2 se describe la obtención de los datos, para la Sección 3 se explica cómo y porque se extendió la taxonomía base, la Sección 4 muestra el procedimiento para completar los valores faltantes del repositorio, la Sección 5 expone las pruebas y la Sección 6 presenta los resultados obtenidos y las conclusiones.
Se consultaron fuentes de reportes de incidentes, que fueran de acceso libre en Internet; es normal que las empresas que han sido blancos de ataques informáticos deseen mantener cierto nivel de reserva sobre las características del ataque, muchas veces mantienen en secreto la ocurrencia del incidente. Por otra parte los incidentes reportados en un sitio Web suelen ser los mismos citados en otros sitios, estos factores minimizan el número de ataques que pueden reunirse, no obstante se identificaron tres fuentes de fácil consulta y que proporcionaban gran número de datos sobre los incidentes:
- Web Hacking Incident DataBase: Es un proyecto del Consorcio de Seguridad de Aplicaciones Web (Web Application Security Consortium) [3], dedicado a mantener una lista de incidentes de seguridad informática en aplicaciones Web. En esta se incluyen solo ataques dirigidos, aquellos que violaron la seguridad de las aplicaciones web. El sitio cuenta con filtros de búsqueda capaces de consultar los incidentes registrados, como: método de ataque, debilidad de la aplicación Web, resultado y entidad atacada. De esta fuente se adquirieron 569 incidentes con fecha de ocurrencia fuera mayor al 2007. Las características de los incidentes de esta base de datos se resumen en la Tabla I.
- Chronology of Data Breaches: Open Security Foundation, es fuente de información acerca de violacio-nes de seguridad. La base de datos incluye datos como: el tipo de violación de seguridad, el tipo de en-tidad atacada, la ubicación geográfica de la entidad y la descripción del ataq ue [4]. Se tomaron 579 re-gistros ocurridos entre el 2005 y el 2010, teniendo como condición que la violación de seguridad fuera HACK (Hacking o Malware) o DISC (Divulgación no intencional). Las características de los incidentes de esta base de datos se resumen en la Tabla II.
- COL-CSIRT: Es un proyecto de investigación de la Universidad Distrital [5] con el fin de crear un equipo de respuesta a incidentes de seguridad informática. El grupo de investigación cuenta con una base de datos del centro de respuesta a incidentes y ataques con código malicioso; esta información proviene de las siguientes fuentes: Centro de estudios de respuesta y tratamiento de incidentes de seguridad de Brasil [6], y Centro de respuesta a incidentes de seguridad de Inteco [7]. Se obt uvieron 169 incidentes desde Febrero de 2008 a Octubre de 2010.


Los datos de estas tres fuentes se estandarizaron según la taxonomía Sandia mencionada anteriormente. Para ello se recorrieron de manera manual y se llenaron los campos definidos en la taxonomía.3.
Luego de leer, analizar y clasificar los incidentes, se encontró dificultad en completar campos como la Herramienta, el Objetivo, el Atacante y el Resultado no autorizado, pues esta información se extrajo de la descripción proporcionada, que en más del 50% de los casos no era lo suficientemente explicativa. Para esos incidentes fue necesario una consulta adicional en Internet, en distintos artículos para tener mayor conocimiento sobre los ataques y completar los datos de clasificación [8][9][10][11][12][13].
Por otra parte cabe resaltar que los campos extras de la WHID almacenan información de gran interés para iden-tificar los incidentes, entre los que se cuentan:
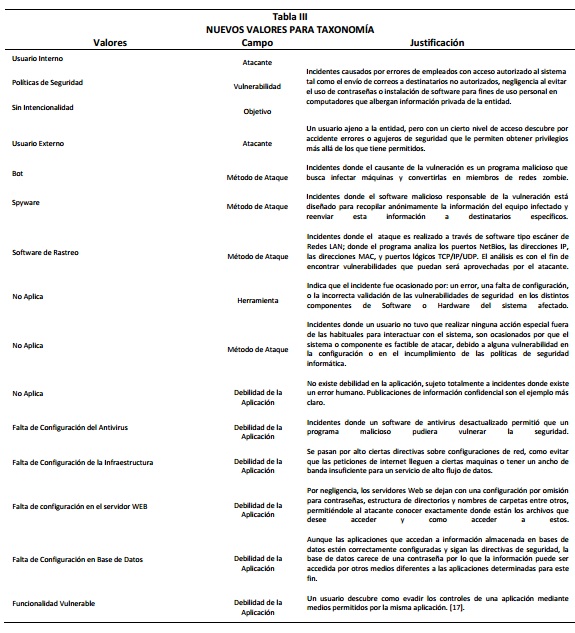
- Debilidad de la Aplicación: Especifica el fallo que permitió la ocurrencia del incidente, con los siguientes posibles valores: Autenticación Insuficiente, Autorización insuficiente, Entropía insuficiente, Falta de Configuración del Antivirus, Falta de configuración de Infraestructura, Falta de configuración en el Servidor Web, Falta de configuración en la base de datos, Falta de configuración de la aplicación, Funcionalidad vulnerable, Indexado Inseguro, Insuficiente anti-automatización, Insuficiente expiración de sesión, Insuficiente recuperación de contraseña, Manejo inapropiado de entradas, Manejo inapropiado de salidas, Permis os inapropiados sobre archivos del sistema, Protección insuficiente en la capa de transporte y Proceso de validación insuficiente.
- Método de Ataque: Proporciona información detallada acerca de cómo se vulneró la seguridad y se obtuvo el acceso no autorizado, con los siguientes posibles valores: Abuso de funcionalidad, Automatización de procesos, Acceso no autorizado, ARP Spoofing, Bot, Clickjacking, Comando del sistema operativo, Cross Site Request Forgery (CSRF), Cross Site Scripting (XSS), Denegación de servicio, Desconocido, Divulgación no intencional, Fuerza bruta, Gusano, Hijacking DNS, Inclusión de archivo local, Inclusión de archivo remoto, Localización predecible de recursos, Navegación forzada, Phishing, Secuestro de dominio, Secuestro de sesión, Spyware, Software de rastreo, SQL Injection, Suplantación de contenido, Troyano y Virus.
Estos dos campos, por los valores que pueden tomar, dan un panorama más exacto del incidente y por tal motivo fueron incluidos en la taxonomía, generando una primer mejora.
A medida que se fueron analizando más incidentes se hicieron latentes nuevas necesidades, por una parte muchos de los valores de la taxonomía base (inclusive de los dos nuevos campos tomados de WHID) no abarcaban características esenciales de los incidentes y por otra parte, debido a la información que se suele reportar y encontrar sobre los incidentes, el campo Acción no podría ser diligenciado. Por las razones anteriores, en primer lugar se eliminó el campo Acción de la taxonomía y en segundo lugar se crearon nuevos valores para la clasificación, en la Figuras 2 y Figuras 3 se muestra la taxonomía final extendida. En la Tabla III se resumen los nuevos valores creados para la taxonomía con su justificación. Estos a su vez, permitieron clasificar finalmente todos los incidentes encontrados cubriendo un rango más amplio que el de la clasificación existente, además de proporcionar mayor conocimiento del vector de ataque.
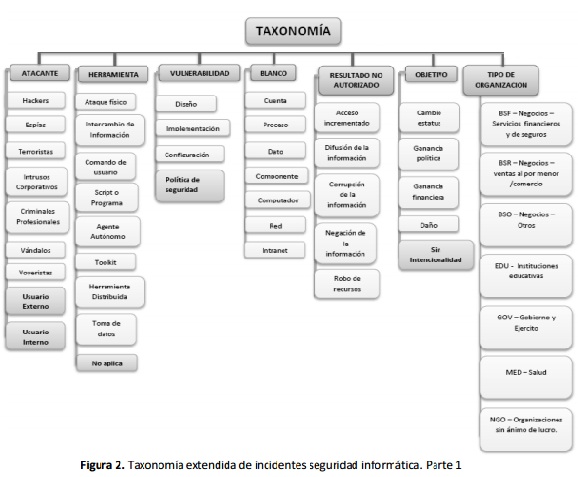
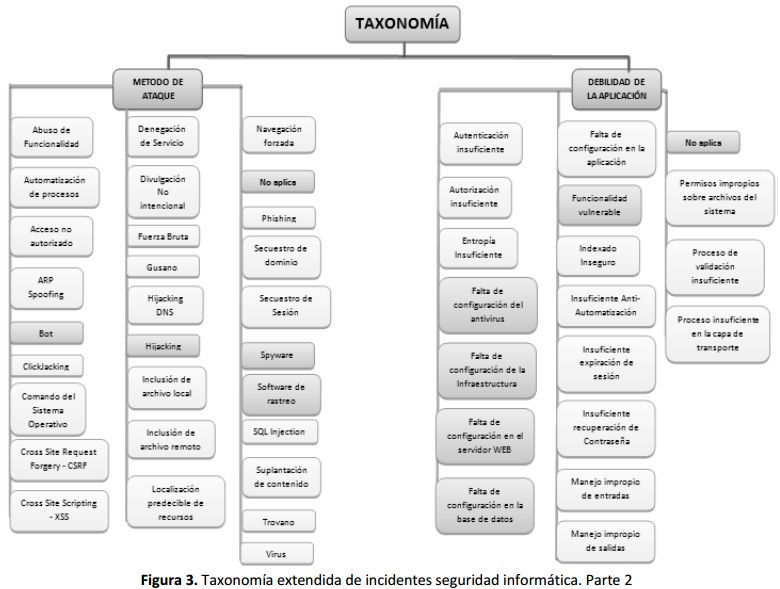
4. TRATAMIENTO DE VALORES FALTANTES
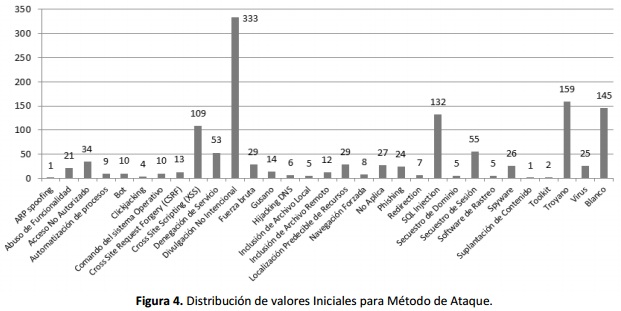
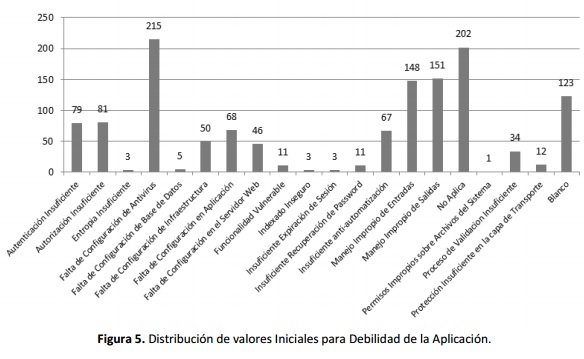
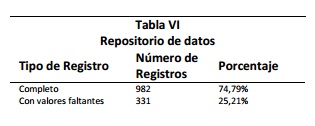
Una vez finalizado el proceso de estandarización de datos, el número total de registros recopilados y descritos de acuerdo a la taxonomía mejorada fue de 1313 incidentes de seguridad, no obstante, debido a la precaria información relacionada para el 25% de los incidentes, no fue posible completar todos los campos descriptivos, este problema es más conocido en la literatura como missing-values, valores faltantes o en blanco. De los 1313 registros, 982 tuvieron todos los campos completos, mientras que 331 presentaron uno o más valores faltantes, los casos de mayor impacto se presentaron en los campos Método de Ataque 145 registros, Debilidad de la Aplicación 123 registros, Vulnerabilidad 144 registros y Herramienta 262 registros con valores faltantes. En las figuras 4 y 5 se puede observar la distribución de valores para los campos Método de Ataque y Debilidad de la Aplicación y se visualiza el alto número de registros con estos campos en blanco.
Tal como lo sugieren autores consultados [14][15][16], las opciones para tratamiento de missing-values son:
- Ignorar el registro cuando tenga gran cantidad de atributos faltantes.
- Llenar el valor faltante de manera manual.
- Usar una constante global para llenar el valor faltante, por ejemplo el texto “desconocido”.
- Usar el valor más probable determinado mediante herramientas basadas en inferencia, tales como el formalismo Bayesiano y árboles de decisión.
- Métodos de aprendizaje supervisado y no supervisado tales como el clustering, o las redes neuronales.
Estas opciones se analizaron de manera individual:
- Ignorar los registros con valores faltantes conllevaría a perder el 25% de los incidentes recopilados.
- Llenar el valor faltante manualmente no es una opción pues el repositorio se construyó de esta manera.
- Definir un valor por omisión de llenado causaría que estos algoritmos consideraran dicha constante como un valor de "interés"; calcular un valor promedio es una buena opción para repositorios cuyos campos sean numéricos, sin embargo en este caso son categóricos con lo cual no es posible hallar un promedio [17] [18]. Los métodos de aprendizaje supervisado y no supervisado serán usados a futuro en tareas propias de la minería de datos [19], tales como la detección de outliers y el análisis de cluster en el momento en que el repositorio este estandarizado totalmente. Dado este análisis, la estimación del valor más probable se escogió como la opción más conveniente para el caso de estudio. La técnica utilizada se define con detalle a continuación.
4.1. Estimación de valores faltantes mediante un enfoque Bayesiano.
Se utilizó una técnica con base en la propuesta de estimación de valores categóricos faltantes de Xiao-Bai Li [20], donde los valores faltantes de tipo categóricos se estiman como un problema de clasificación mediante cálculos probabilísticos, es decir se calcula el valor faltante del atributo de interés, como la clase (categoría) más probable dados los valores para los restantes atributos presentes. Esta probabilidad se obtiene mediante una aproximación Bayesiana: Sea c1,...,cL particiones del espacio muestral. Entonces, para cada evento X en el espacio muestral,
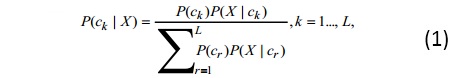
Donde P(ck) es llamada la probabilidad a priori y P(ck|X) es la probabilidad a posteriori.
Se considera un conjunto de datos con un atributo de clase de dos tipos posibles, c1 y c2, y M-1 atributos que no son de clase, X1,...,XM-1. Para un nuevo registro x=(x1,..., xM-1) que deba ser clasificado; el clasificador Bayesiano asigna al valor de clase a c1 si P(c1|x) > P(c2|x), de lo contrario asigna a c2. La probabilidad a posteriori P(ck|x) puede ser derivada del Teorema de Bayes (1). El proceso involucra la estimación de P(ck) y P(x|ck) a partir de los datos. Mientras que P(ck) es fácil de obtener, evaluar a P(x|ck) es muy costoso en cuanto a recursos computacionales para conjuntos de datos con una alta dimensionalidad. Para sortear este inconveniente, se asume que los atributos son condicionalmente independientes entre sí. Bajo esta suposición, P(x|ck) puede ser fácilmente calculado por:
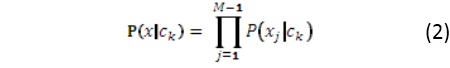
Lo que se conoce como un clasificador ingenuo de Bayes (Naive Bayes classifier).
El método permite estimar las probabilidades de múltiples atributos faltantes con base en los atributos existentes. Dado un conjunto de datos con N registros y M atributos categóricos, X,...,XM, sea Li el número de categorías en Xi, y sea Ni el número de registros con Xi valores conocidos, y Nij el número de registros donde Xi es igual a la k-esima categoría cij. Adicionalmente, sea Njr|ik el número de registros donde Xj es igual a la r-esima categoría cjr, dado Xi=cik con j ≠ i. El proceso para completar los valores faltantes a partir de este método se describe en la Tabla IV.

4.2. Ejemplos de estimación
Consideremos una versión simplificado de nuestro repositorio, compuesto por 4 atributos categóricos: ATACANTE, HERRAMIENTA, VULNERABILIDAD y OBJETIVO. Suponemos que el repositorio se compone de 20 registros, donde cuatro de estos registros presentan valores faltantes como se observa en la Tabla V,
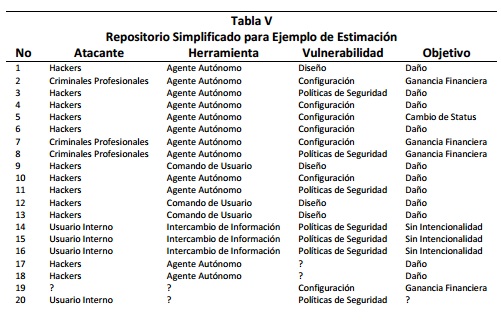
para los registros 17 y 18 se observa que el campo faltante es VULNERABILIDAD, en este caso iniciamos calculado las probabilidades a priori para el mismo:
P(Diseño) = 4/18
P(Configuración) = 7/18
P(Políticas de Seguridad) = 7/18
A continuación se calculan las probabilidades condicionales para el atributo ATACANTE cuando sea igual a Ha-ckers dado cierto valor de VULNERABILIDAD:
P(Hackers | Diseño) = 4/4
P(Hackers | Configuración) = 4/7
P(Hackers | Políticas de Seguridad) = 2/7
De la misma forma calculamos las probabilidades condicionales para {Herramienta = Agente Autónomo} y {Objetivo = Daño}
P(Agente Autónomo | Diseño) = 1/4
P(Agente Autónomo | Configuración) = 6/7
P(Agente Autónomo | Políticas de Seguridad) = 3/7
P(Daño| Diseño) = 4/4
P(Daño | Configuración) = 3/7
P(Daño | Políticas de Seguridad) = 2/7
Luego se calculan las probabilidades a posteriori:
P(DI|H,AA,D) = 1/P (4/18)(4/4)(1/4)(4/4) = 0,05556/P
P(C|H,AA,D)=1/P (7/18)(4/7) (6/7) (3/7) = 0,08163/P
P(PS|H, AA,D) =1/P (7/18) (2/7) (3/7) (2/7) = 0,013605/P
DI=Diseño, C= Configuración, PS= Políticas de Seguridad, H=Hackers, AA = Agente Autónomo D = Daño
Finalmente calculamos:
P(DI|H,AA,D) = 0,05556P/0,05556P + 0,08163P + 0,013605P = 0,36844
P(C|H,AA,D) = 0,08163P/0,05556P + 0,08163P + 0,013605P = 0,54133
P(PS|H,AA,D) = 0,013605P /0,05556P + 0,08163P + 0,013605P = 0,09022
Así que el valor más probable y el que reemplazara al valor faltante en los registros 17 y 18 es Configuración, e s-te mismo cálculo se podría llevar a cabo para reemplazar los faltantes de los registros 19 y 20.
El mismo proceso se llevó a cabo con el repositorio real para completar los valores faltantes
4.3. Exclusión de Atributos con Bajo Contenido de Información
Para la estimación Bayesiana realizada, la dimensionalidad del incidente fue reducida, es decir se retiraron las siguientes columnas:
- ENTIDAD, 993 valores distintos.
- FECHA, 842 valores distintos.
- PAIS, el 70% de los incidentes tiene como país de origen a Estados Unidos, el 11% a Colombia, el 1,83% al Reino Unido, 1,29% en India, 1,14% en Australia y 12,34% en otros países.
El motivo de esta reducción se debe a que las columnas ENTIDAD y FECHA, para fines prácticos son identificadores del registro, pues en los incidentes recopilados pocos son reincidentes para una misma ENTIDAD y pocos ocurrieron en una misma fecha, ya que estas columnas manejan un alto rango de valores, no son apt as para agrupar por subconjunto.
En el otro extremo tenemos el campo PAÍS, ya que la mayoría de los incidentes ocurrieron en Estados Unidos, por lo tanto si se considerara en análisis Bayesiano de los valores faltantes sesgaría la decisión hacia el subconjunto definido para ese país. Por las razones anteriores los cálculos de probabilidad de las columnas mencion a-das no se tomaron en cuenta para la estimación Bayesiana aunque siguen haciendo parte del repositorio.
Con el fin de comprobar la efectividad en la estimación de valores faltantes mediante el enfoque Bayesiano y probar el grado de confianza en el repositorio; se realizó una validación contra los registros del repositorio que tenían los datos completos. La distribución final del repositorio se muestra en la Tabla VI:
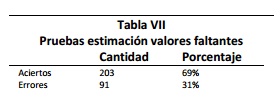
De la porción del repositorio que no tenía valores faltantes, se eligió un subconjunto equivalente al 30% (294 re-gistros). Para cada registro del subconjunto de validación, se eliminó una columna elegida al azar y los valores eliminados fueron calculados con el enfoque Bayesiano descrito, luego se compararon los resultados obteni dos con el valor que tenía el campo inicialmente. Los resultados globales se presentan en la Tabla VII, los resultados discriminados por campo en la Tabla VIII y Figura 6.
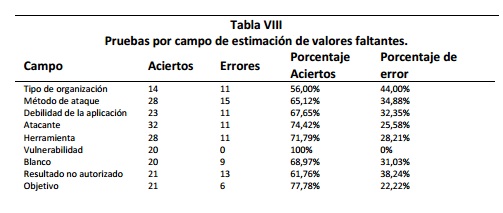
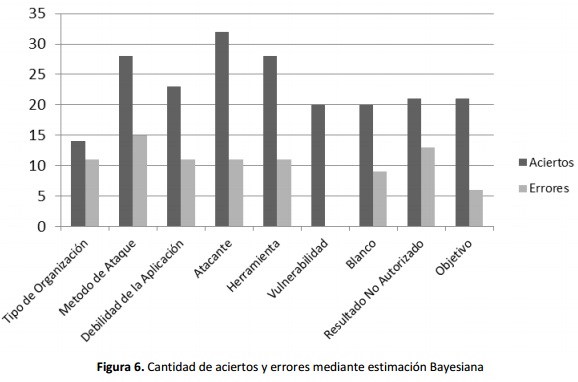
Como se evidencia el porcentaje más bajo de aciertos corresponde al Tipo de Organización, demostrando que no existe una relación estrecha entre este campo y el resto del vector del ataque. Por el contrario la Vulnerabilidad depende totalmente del resto de campos del registro logrando un porcentaje de aciertos del 100%.
El clasificador Bayesiano muestra alta dependencia de la distribución de valores propia del conjunto de datos y obtiene valores acertados para registros que tengan un comportamiento común y conocido para el clasificador, esto se deduce de la inspección de algunos de los registros que no fueron clasificados correctamente como los que se presentan en la Tabla IX.

5.1. Comparación contra el valor promedio
El clasificador fue enfrentado con uno de los métodos más comunes en el tratamiento de los valores faltantes el cual consiste en elegir el valor promedio del campo para completar el registro. Los resultados totales del método del valor promedio se muestran en la Tabla X y los resultados discriminados por campo se presentan en la Tabla XI y Figura 7.
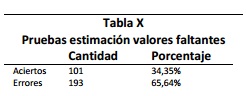
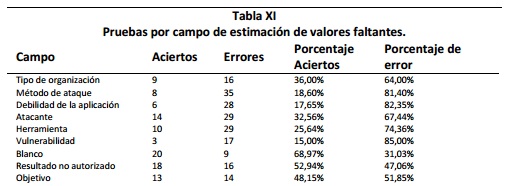
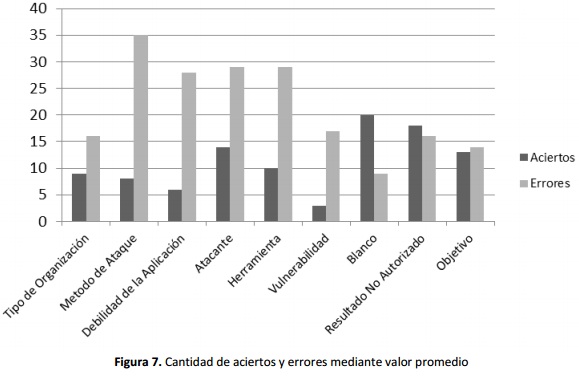
El método del valor por promedio muestra resultados menos efectivos en comparación a los del clasificador Ba-yesiano, el porcentaje de aciertos del clasificador Bayesiano (69%) es más del doble del porcentaje del método del promedio (34%) y además el valor promedio no logró sobrepasar en ninguno de los campos al competidor.
Finalmente se obtuvo un repositorio de 1234 registros con todos los atributos diligenciados (Tipo de Organización, Entidad, Método de Ataque, Debilidad de la Aplicación, País, Fecha, Atacante, Herramienta, Vulnerabilidad, Blanco, Resultado No Autorizado y Objetivo), la técnica usada permitió completar el 76 % de los registros con va-lores faltantes, a pesar de la estimación Bayesiana, fue necesario eliminar 79 registros de los 1313 originales, pues éstos presentaban valores faltantes en las columnas Método de Ataque, Debilidad de la Aplicación, He-rramienta y Vulnerabilidad, es decir una pérdida de información del 44% de la totalidad de atributos usados pa-ra hallar las probabilidades a-posteriori.
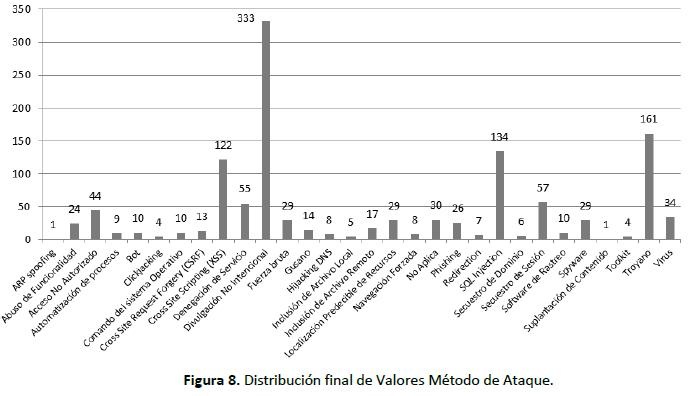
El repositorio final muestra (Figura 8) que los métodos de ataque predilectos son la Divulgación No Intencional (333 incidentes), los troyanos (161 incidentes), la inyección de SQL (134 incidentes) y el Cross Site Scripting (122 incidentes). El uso de Virus comunes se ve rezagado (34 incidentes), al igual que los gusanos (14 incidentes). Los métodos menos populares son Clickjacking y Toolkit (ambos con 4 incidentes), ARP spoofing y Suplantación de Contenido (1 incidente cada uno).
La Divulgación no Intencional fue causada en un 83% de los casos por Usuarios Internos, esto demuestra la insuficiente implantación de Políticas de Seguridad y el énfasis que debe aplicarse a la capacitación de los empleados sobre la importancia de la seguridad de la información. El alto uso de troyanos lleva a la misma conclusión, ya que en el 93% de los casos la debilidad de la aplicación fue Falta de Configuración en el Antivirus.
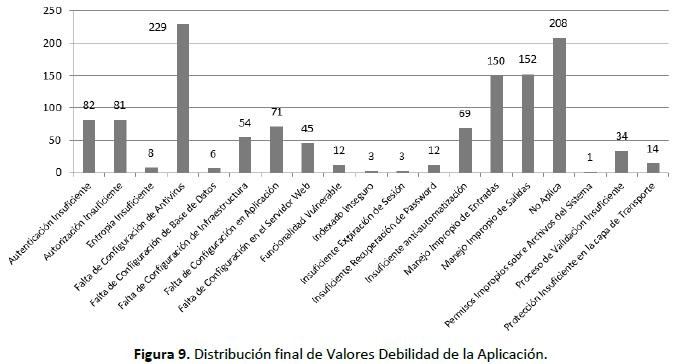
Para los incidentes de SQL Injection y Cross Site Scripting, la Vulnerabilidad fue Implementación en un 87% y 84% respectivamente, la responsabilidad de estos incidentes recae en los desarrolladores del software. La deficiencia en el desarrollo del software se centra en la codificación de la interfaz de usuario como se ve en la Figura 9, con 152 incidentes causados por un Manejo Impropio de Salidas y 150 por Manejo Impropio de Entradas. El número de incidentes de este tipo debería ser tomado en cuenta en las empresas con el fin de analizar la capacidad de los desarrolladores contratados y tomar medidas de tipo gerencial, como capacitar o cambiar el equipo de desarrolladores.
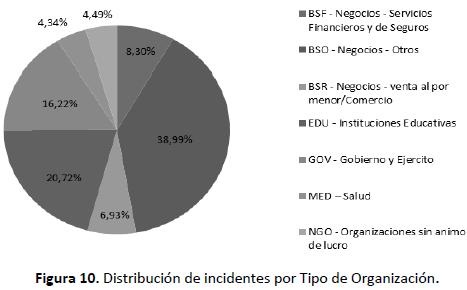
En contra de una suposición popular, las entidades de tipo financiero obtuvieron el cuarto lugar de tipo de en-tidades atacadas, siendo las más vulneradas las que clasifican en la categoría BSO - Negocios - Otros, conformado por empresas de tecnología, medios de comunicación y hoteles entre otros. Por otra parte, las instituciones de-dicadas a la salud son las menos atacadas. En la Figura 10 se observa la distribución de incidentes por categoría.
7. CONCLUSIONES
El reporte de incidentes de seguridad es una práctica que cada empresa debe tener en cuenta, esto con el fin de permitir rastrear y analizar los ataques y sus posibles relaciones, teniendo en cuenta que en Colombia las entidades financieras están reglamentadas por la circular 052 del 2007 de la Superintendencia Financiera [21] que fijó un estándar para la seguridad y calidad en el manejo de la información, enfocada a los datos de los clientes asegurando confidencialidad y disponibilidad. La taxonomía propuesta en este artículo se propone como solu-ción para el reporte de los incidentes, pues permite determinar los perfiles de los mismos, con campos fáciles de diligenciar, evitando que los reportes sean descripciones ambiguas.
Según la norma ISO 27001[22] un sistema de gestión de seguridad (SGSI) debería implementarse en institucio-nes de cualquier naturaleza; en este sentido es de gran utilidad contar con un registro de los incidentes informá-ticos y un análisis estadístico de los mismos que permita encontrar las causas de un incidente que tengan como consecuencias inconformidades respecto a un conjunto de requerimientos.
De acuerdo a lo anterior, como trabajo futuro fruto de esta investigación, se propone la publicación del repositorio final obtenido en un sitio Web, además del desarrollo de una página que permita diligenciar los campos de la taxonomía propuesta para reportar nuevos incidentes de seguridad informática, con el fin de alimentar el repositorio con nuevos registros. Una vez esto se logre, el repositorio puede ser utilizado para investigaciones similares y/o enfocadas a la minería de datos, que permitan obtener conclusiones de gran valor para el área de seguridad informática, un tema que en la actualidad tiene una relevancia trascendental en el mundo.
GLOSARIO

REFERENCIAS
- John D. Howard, Thomas A. Longstaff. “A Common Language for Computer Security Incidents”. Sandia National Laboratories, Octubre 1998.
- Carlos Carvajal, Diego Bayona, Análisis de Incidentes de Seguridad Informática Mediante Minería de Datos, para Modelado de Comporta-miento y Reconocimiento de Patrones, Tesis para acceder al título de Ingeniería de Sistemas de la Universidad Francisco José de Caldas, Bogotá, Colombia, 2012
- Web Application Security Consortium. “Web Hacking Incident DataBase”, http://projects.webappsec.org/w/page/13246995/Web-Hacking-Incident-Database
- Privacy Rights ClearingHouse, “Chronology of Data Breaches”. http://www.privacyrights.org/data-breach
- COL-CSIRT, Grupo de Investigación Universidad Distrital. http://gemini.udistrital.edu.co/comunidad/grupos/arquisoft/colcsirt/
- CERT Brasil. “Centro de estudios de respuesta y tratamiento de incidentes de Seguridad de Brasil”.
- INTECO España — Instituto Nacional del Tecnologías de la Comunicación. Centro de respuesta a incidentes de seguridad TIC. http://cert.inteco.es
- "Hackers hit Tunisian websites" ALJAZEERA, Red de Noticias, 3 de Junio 2011, http://www.aljazeera.com/news/africa/2011/01/201113111059792596.html
- "Secunia recovers from DNS redirection hack" The Register, Publicación Online de Tecnología, 26 de Noviembre de 2010. http://cert.inteco.es
- "Cops: Hacker Posted Stolen X-rated Pics on Facebook" PCWorld, Magazín de Computación, 2 de Noviembre de 2010. http://www.pcworld.com/businesscenter/article/209584/cops_hacker_posted_stolen_xrated_pics_on_facebook.html
- COMPUTERWORLD, Magazín de Computación. http://www.computerworld.com/s/article/9149218/Bank_sues_victim_of_800_000_cybertheft
- "Bank sues victim of $800,000 cybertheft" The Washington Post, Periódico de la ciudad de Washington, 26 de Enero de 2010. http://www.washingtonpost.com/wp-dyn/content/article/2010/03/18/AR2010031805464.html
- "Hackers Take Over BP Twitter Feed" FOX NEWS, Red de noticias, 27 de Mayo de 2010. http://www.foxnews.com/tech/2010/05/27/hackers-bp-twitter-feed/
- Jiawei Han, Micheline Kamber. “Data Mining: Concepts and Techniques”. Morgan Kaufmann Publishers 2000, Capitulo 3 "Data Preprocesing".
- Roderick J. A. little, Donald B. Rubin. "Statistical Analysis with Missing Data". Capitulo 6 "Theory of Inference Based on the Likeli-hood Function".
- Dorian Pyle. "Data Preparation for Data Mining". Capitulo 8 "Replacing Missing and Empty Values". http://www.temida.si/~bojan/MPS/materials/Data_preparation_for_data_mining.pdf
- Jaisheel Mistry. "Estimating Missing Data and Determining the Confidence of the Estimate Data"Seventh International Conference on Machine Learning and Applications, 2008.
- Ludmila Himmelspach. "Clustering Approaches for Data with Missing Values: Comparison and Evaluation",Institute of Computer Science Heinrich-Heine-Universität Düsseldorf, 2010.
- Jiawei Han, Micheline Kamber. “Data Mining: Concepts and Techniques”. Morgan Kaufmann Publishers 2000, Capitulo 8 "Cluster Analysis".
- Xiao-Bai Li . “A Bayesian Approach for Estimating and Replacing Missing Categorical Data”. ACM Journal of Data and Information Quality, Vol. 1, No. 1, Article 3, Junio 2009.
- “ABC de la Circular Externa 052 DE 2007", Comunicado de Prensa, Superintendencia Financiera de Colombia, Noviembre 7 de 2007. http://www.superfinanciera.gov.co/
- “ISO/IEC 27001 : 2005 Tecnología de la Información- Técnicas de seguridad- Sistemas de gestión de seguridad- Requerimientos ”. Están-dar Internacional, Octubre 200 http://www.iso.org/iso/home.html

Este trabajo está autorizado por una Licencia Attribution-NonCommercial-NoDerivs CC BY-NC-ND.
Licencia
![]()
A partir de la edición del V23N3 del año 2018 hacia adelante, se cambia la Licencia Creative Commons “Atribución—No Comercial – Sin Obra Derivada” a la siguiente:
Atribución - No Comercial – Compartir igual: esta licencia permite a otros distribuir, remezclar, retocar, y crear a partir de tu obra de modo no comercial, siempre y cuando te den crédito y licencien sus nuevas creaciones bajo las mismas condiciones.

2.jpg)