
DOI:
https://doi.org/10.14483/23448350.6498Published:
06/26/2014Issue:
Vol. 19 No. 2 (2014): May-August 2014Section:
Science and EngineeringServicio Amazon Web Services de clasificación primaria de imágenes de fuentes hídricas del piedemonte amazónico que usan redes neuronales-Service Amazon Web Services primary classification images of the Amazon piedmont water sources using neural networks
Keywords:
servicio web, Android, red neuronal, clasificación de imágenes, ecosistemas acuáticos, Amazonía, léntico, lótico. (es).Downloads
References
Gobernación de Caquetá (2008). Plan departamental de desarrollo 2008-2011. Ordenanza No. 008 de 28 de mayo de 2008.
Duivenvorden, J. F. y Lips, H. (1993). Ecología del paisaje del medio Caquetá. En J. Saldarriaga y T. Vander Hammen (eds.), Estudios de la Amazonía Colombiana, 3.
Universidad de la Amazonia (2011). Vicerrectoría de Investigaciones y Posgrados.
Pajares Martinsanz, G. (2002). Visión por computador. Imágenes digitales y aplicaciones. México: Alfaomega.
Amazon.com (2013, agosto). Amazon web service. Recuperado de http://aws.amazon.com/es/careers/
Visual-paradigm.com (2013, agosto). Express UML tool. Recuperado de http://www. visual-paradigm.com/
Código (2013). Aplicaciones de redes neuronales en JAVA. Recuperado de http://pabloborbon.com/2010/03 /aplicación -de-redes-neuronales-en-java/
Martínez F., Díaz M. C., Martín M. T., Rivas, V. M. y Ureña, L. A. (2009). Aplicación de redes neuronales y redes bayesianas en la detección de multipalabras para tareas IR. Jaén: Universidad de Jaén.
How to Cite
APA
ACM
ACS
ABNT
Chicago
Harvard
IEEE
MLA
Turabian
Vancouver
Download Citation
Servicio Amazon Web Services de clasificación primaria de imágenes de fuentes hídricas del piedemonte amazónico que usan redes neuronales1
Service Amazon Web Services primary classification images of the Amazon piedmont water sources using neural networks
Serviço Amazon Web Services imagens de classificação primárias das fontes de água da Amazônia Piemonte utilizando redes neuraisão topológica de um tipo semi reboque caixa aberta
Edwin Eduardo Millán Rojas2
José Nelson Pérez Castillo3
1Artí;culo de investigación
2Universidad de la Amazonia. Florencia, Colombia, Contacto: e.millan@udla.edu.co
3Universidad Distrital Francisco José de Caldas, Bogotá, Colombia, Grupo de Investigación en Ingeniería y Diseño Dising. Contacto: jnperez@udistrital.edu.co
4Universidad Distrital Francisco José de Caldas, Bogotá, Colombia, Grupo de Investigación en Ingeniería y Diseño Dising. Contacto: cabohorqueza@udistrital.edu.co
Fecha de recepción: Agosto de 2013, Fecha de aceptación: Abril de 2014
Resumen
En la presente investigación se parte de la determinación de un problema que se encuentra hoy en día en muchos campos de las organizaciones que se dedican a la investigación, como lo es la Universidad de la Amazonia, en la cual existen grupos de investigación que generan altos volúmenes de información gráfica. Estos fueron tomados como base para realizar un procesamiento inteligente que permita clasificar los tipos de agua en su nivel primario y determinar si se puede llevar esta clasificación a un servicio web desplegado en la nube y consumido desde una aplicación móvil desarrollada para dispositivos con sistema operativo Android.
Palabras clave: servicio web, Android, red neuronal, clasificación de imágenes, ecosistemas acuáticos, Amazonía, léntico, lótico.
Introducción
Los últimos años han visto un rápido incremento del tamaño de las colecciones de imágenes digitales (médicas, históricas, policiales, pictóricas, etc.). Esta situación plantea una necesidad básica: procesamiento y clasificación de las imágenes deseadas entre una extensa colección.
Los métodos tradicionales de procesamiento y clasificación de la información se muestran insuficientes e inadecuados por falta de tiempo, recurso de cómputo, espacio de almacenamiento, entre otros diversos motivos. En este campo, aparecen los conceptos de procesamiento inteligente, mallas computacionales (computación grid) e imágenes digitales, que pretenden dar un mayor alcance al proceso de clasificación y ayudan a tener la información con los parámetros solicitados por los usuarios expertos.
En la presente investigación se desarrolla una solución a la clasificación de imágenes digitales a partir de la utilización de un algoritmo inteligente. Esta información posee un volumen de datos necesarios en los procesos de investigación, como lo son las imágenes digitales tomadas a los ecosistemas acuáticos amazónicos, las cuales pueden ayudar a determinar especies y elementos nuevos en el campo de la biología animal o vegetal.
Usando una red neuronal y entrenándola para desplegar la aplicación realizada en Java en un servidor apache ubicado en la nube para desplegar un servicio web que pueda ser consumido por una aplicación Android desde cualquier celular, tableta o dispositivo móvil que posea este sistema operativo, esta interface se desarrolló en el IDE de eclipse usado por Android, el cual cuenta con todas las herramientas necesarias para realizar esta labor.
Utilizando el algoritmo desplegado, se demostró que sí es posible mejorar los tiempos de clasificación cuando se presentan elevados volúmenes de información, en nuestro caso imágenes de ecosistemas acuáticos amazónicos.
Materiales y métodos
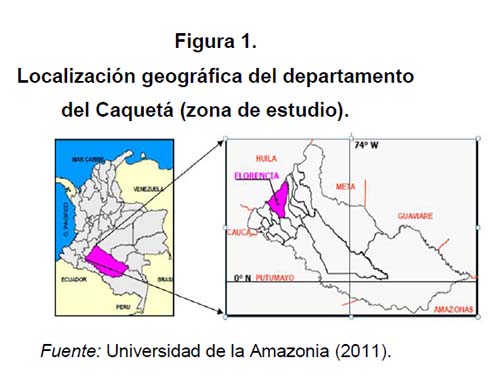
Zona de estudio de los ecosistemas acuáticos amazónicos del departamento del Caquetá
Ubicación
El departamento de Caquetá (figura 1) está situado en el noroeste de la región amazónica, al sur de Colombia, sobre la margen izquierda del río Caquetá, entre los 2º 58´ N y 0º 40´ S y los 71º 30´ y 76º 15´ O (Gobernación de Caquetá, 2008). Con un área de 88 965 km2, posee una población aproximada de 420 337 habitantes, 54 % de ellos como población rural, quienes destinan solo 0.5 % del territorio departamental para la producción agrícola —0.10 % en cultivos transitorios y barbechos y 0.40 % en cultivos permanentes o semipermanentes— y lo demás para el establecimiento de pasturas para la producción ganadera (Gobernación de Caquetá, 2008). El sur de la Amazonía colombiana posee dos grandes vertientes que desembocan directamente al río Amazonas. La primera, la del río Caquetá, posee a lo largo de su canal principal 2280 km (Duivenvorden y H. Lips, 1993). La segunda cuenca, la del río Putumayo, tiene una longitud aproximada de 2000 km y recorre el territorio colombiano en 1550 km. Además, hallamos las cuencas de los ríos Vaupés, Guanía y en el sur de la región se encuentra 176 km de río Amazonas (Gobernación de Caquetá, 2008).
Clasificación general del tipo de agua
La importancia de los sistemas hídricos o acuáticos de la región es vital como parte sustantiva del ciclo climático mundial, así como por ser una de las principales fuentes de recursos hídricos, hidrobiológicos y económicos de la región. A continuación, se menciona la clasificación detallada de las fuentes hídricas según [4]:

Para el desarrollo inicial de la investigación, se tomaron de la anterior clasificación general dos parámetros generales para determinar inicialmente una clasificación primaria y luego profundizar con trabajos futuros en cada una de las ramas que se extienden. Esta clasificación se basa en determinar si una fuente hídrica es léntica o lótica, con este fin se realizaron diferentes tomas a los afluentes para realizar inicialmente una clasificación manual. Los lugares que se visitaron fueron:
- Cananguchales Morelia
- Humedal San Luis
- Río Bodoquero Morelia
- Río El Pescado
- Río El Sarabando
- Río Fragua Chorroso
- Río Hacha
- Río Caraño
- Cascada
- Madre Vieja Aeropuerto
- Puente Venecia
- Río Orteguaza
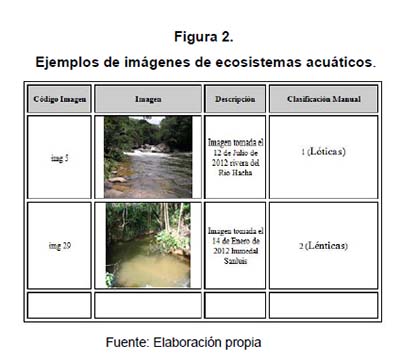
Listado de ecosistemas acuáticos visitados, de los cuales se poseen imágenes digitales de alrededor de unas 1000 muestras. Un ejemplo de aguas lóticas y lénticas se ven en la figura 2:
Red neuronal backpropagation
Algoritmo
Se establecieron los criterios por los cuales la red neuronal con el algoritmo de propagación hacia atrás se usó como la técnica adecuada para construir el servicio sobre la plataforma de computación distribuida, para profundizar en los conceptos de la unidad básica de una red neuronal, y se lleva a cabo un recorrido por el algoritmo de propagación hacia atrás, y desde la óptica del cálculo se puede analizar para luego llevar el algoritmo a un lenguaje de programación.
Se escogió la técnica de redes neuronales con el algoritmo de propagación hacia atrás (backpropagation) de acuerdo con los siguientes criterios:
- Las redes neuronales son la técnica de la inteligencia artificial más usada para la clasificación y determinación de formas en imágenes digitales, como se demuestra en la alta documentación que se halla en este tema.
- El algoritmo de propagación hacia atrás se basa en un entrenamiento supervisado que para el caso de estudio se puede determinar mediante las variables de entradas al sistema e inicializarlo de forma controlada, verificando en el sistema la respuesta de aquel.
- La investigación busca establecer si se pueden mejorar los tiempos de clasificación usando la computación en la nube, a través de un servicio computacional, por lo cual las redes neuronales se ajustan a los requerimientos de un alto coste computacional para el procesamiento de la información, elemento fundamental para corroborar su eficiencia en y rendimiento (Pajares, 2002).
- Con las redes neuronales supervisadas, se pueden dividir en dos momentos su entrenamiento y el procesamiento de la información. La mayoría de las técnicas de procesamiento inteligente estudiadas conllevan entrelazar el aprendizaje con el procesamiento, convirtiendo esto en un problema para el investigador debido a que puede generar resultados inesperados. Con la técnica de la red neuronal supervisada se puede controlar en un tiempo prudencial los resultados de la etapa de entrenamiento, para luego pasar a la etapa de clasificación.
Amazon Web Service (AWS)
Amazon Web Services (AWS) es una unidad de negocio de Amazon.com dinámica y en crecimiento. Amazon Web Services lleva desde principios de 2006 proporcionando a empresas de todas las magnitudes con una plataforma de servicios web de infraestructura en la nube (Amazon.com, 2013).
Para el desarrollo del servicio se utilizó la plataforma de Amazon, la cual permite tener acceso desde la nube al recurso y se puede usar en diferentes aplicaciones. Esto toma importancia debido al trabajo de los investigadores, quienes deben ir al terreno para poder realizar la captura de datos y realizar una clasificación primaria de la información; aquí es donde los dispositivos móviles y sus aplicaciones entran a desempeñat un papel estratégico para apoyar las investigaciones.
Se escogió la plataforma AWS por su condición de disponibilidad, durabilidad, capacidad de autenticación de usuarios, reducción en la redundancia en el almacenamiento y porque se puede trabajar conectado o desconectado.
Herramientas de desarrollo
Análisis y diseño
Para estas etapas se usaron las técnicas tradicionales de elicitación en la ingeniería de requerimientos, como entrevistas, arqueología de documentos, etc. Para sistematizar la información obtenida se utilizó visual-paradigm.com, que permite la captura de requerimientos, la consolidación de aquellos y la elaboración de los diseños usando lenguaje de modelamiento unificado (UML, por su sigla en inglés), así como se cuenta con la posibilidad de REVISTA CIENTÍFICA / ISSN 0124 2253/ MAYO - AGOSTO DE 2014 / No. 19 / BOGOTÁ, D.C. generar la estructura básica en el lenguaje que se desee, permitiendo ahorrar tiempo en la escritura de código.
Implementación
Se utilizó el IDE de NetBeans 7.1, el cual a través de su módulo de desarrollo EE permite realizar aplicaciones web y desplegar servicios web para poder ser consumidos en aplicaciones móviles.
Metodología
Para solucionar los objetivos propuestos, se ha definido una metodología enmarcada dentro de dos fases: una fase teórica que pretende lograr seleccionar un algoritmo para la clasificación automática de imágenes, apropiadas al contexto de implementación del servicio y una fase de desarrollo que pretende implementar en una plataforma en la nube un servicio que implemente el algoritmo adaptado para la clasificación de imágenes digitales (tabla 2).
Diseño e implementación
Desarrollo de una aplicación usando el algoritmo backpropagation para la clasificación de imágenes digitales
Preprocesamiento de las imágenes
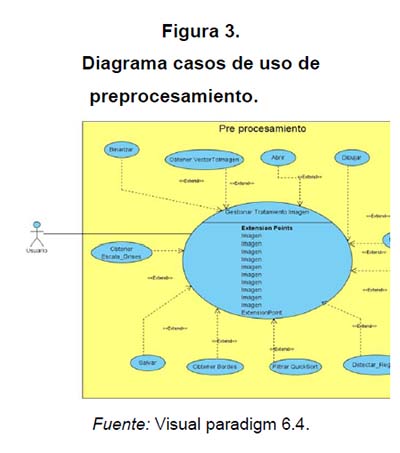
Se desarrolló un servicio web para tomar una subimagen de 3 × 3 pixeles de cada imagen y descomponer esta muestra, obteniendo de esta forma tres matrices (rojo, verde y azul), las cuales fueron procesadas por separado con el objeto de determinar cuál de los tres rangos era más acertado. Esto se realizó a partir de una variable de entrada, la cual determina el ruta del directorio donde se encuentran las imágenes que previamente se deben etiquetar con el siguiente formato de nombre/directorio/imágenes/img(No).jpg.
Para llevar a cabo este procedimiento, se establecieron los siguientes procesos: gestionar tratamiento de imagen, obtener vector imagen, abrir imagen, dibujar imagen, pintar región, obtener región, detectar región, filtrar Quicksort, obtener bordes, salvar imagen, obtener escala de grises, binarizar (figura 3).
En img(N).jpg, N es el valor que cambia en el directorio para ser procesadas de forma secuencial y no requerir subir cada una de las imágenes; como resultado de este servicio se obtienen dos archivos .txt, los cuales devuelven la media y la mediana de una muestra de pixeles de 3 × 3 tomada del centro de la imagen.
Una vez implementada la aplicación procedemos a obtener los vectores de las muestras de la imagen en un conjunto de matrices que nos reflejan los valores en rojo (red), azul (blue) y verde (green) (figura 4).
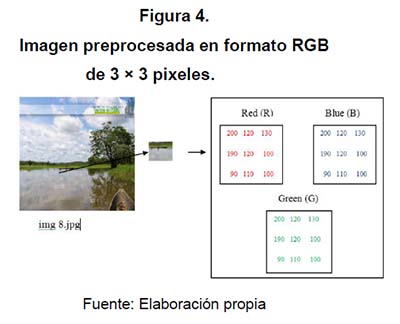
Este mismo procedimiento se realizó con 20 conjuntos de más de 50 imágenes cada uno, dando como resultado el procesamiento de 1000 muestras, las cuales fueron sometidas a un análisis de varianza o Anova permitiendo estudiar si existía una variabilidad en el conjunto de datos en cada una de las matrices definidas RGB.
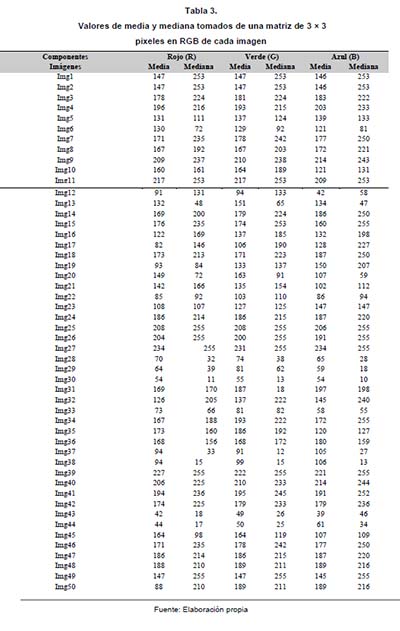
Realizados los análisis y encontrados los conjuntos que permitieron determinar el posible comportamiento del agua, se halló que al determinar la suma de los cuadrados de los grupos (lóticos y lénticos) se determinó que el mejor comportamiento de las muestras se presentaba en la banda verde G, donde se definieron unos rangos que permitieron establecer en 92 % la variabilidad de las muestras en la media y la mediana.
Este comportamiento determina que existe un rango uniforme dentro de la distribución de las muestras para determinar un techo donde se defina la imagen representativa de una de las dos salidas que se pretenden obtener. Los intervalos de confianza que se determinaron se muestran en la tabla 4.
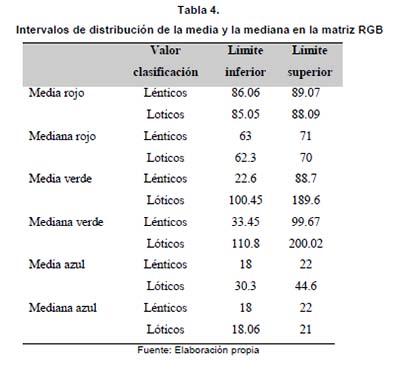
Por el análisis estadístico se estableció que la matriz en verde es la que permite obtener un rango de separación confiable para determinar el tipo de clasificación con la imagen, por lo cual las entradas de la red neuronal serán los valores de la media y la mediana en el componente G (verde) de la imagen en formato jpg.
Diseño de la red neuronal con el algoritmo seleccionado (backpropagation)
Se determinó construir una red neuronal backpropagation con entrenamiento supervisado en el lenguaje de programación Java, para poder llevar el prototipo a un servicio web y luego implementarlo sobre la nube. Para tal fin es necesario determinar que se debe modificar del algoritmo inicial de la red neuronal establecida para adaptarlo a un servicio web. Así, se partió de una red neuronal backpropagation ya establecida en Java, la cual estaba disponible en la web, cuyo autor se referencia en Código (2013), el cual autoriza públicamente usar su código fuente.
Tomando este algoritmo en Java como base, se procedió a establecer la arquitectura posible para determinar el tipo de ecosistema acuático que se presentaba en las imágenes tomadas como muestras para la ejecución del servicio. La red neuronal seleccionada consta de la siguiente arquitectura 2:25:25:2 (figura 5), donde se determina la clasificación primaria de los ecosistemas acuáticos amazónicos de aguas quietas (lénticos) o de aguas corrientes (lóticas).
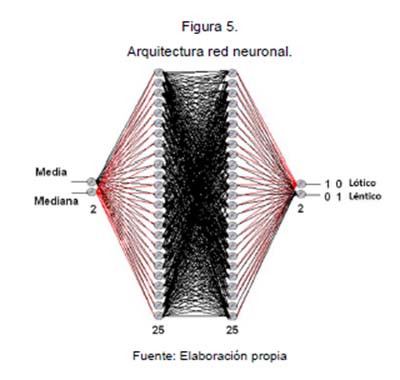
Elaboración de una aplicación en Java para el entrenamiento de la red neuronal
Definidas las entradas de la red neuronal como los elementos de la media o promedio y la mediana del componente G de la imagen RGB, se procedió a establecer la mejor arquitectura posible realizando múltiples ensayos y logrando obtener una red de 2:25:25:2, la cual se realizó en Java con el IDE NetBeans, para obtener el conjunto de los wi que permitieran poner a funcionar de forma correcta la red neuronal en el servicio. El diseño de la aplicación basado en casos de uso se puede ver en la figura 6.
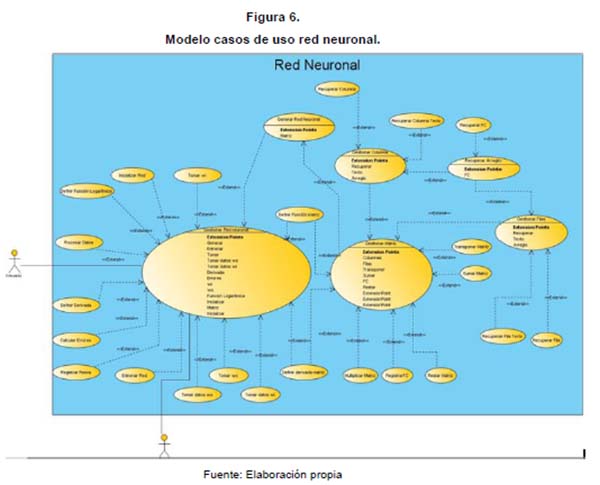
Elaboración de la aplicación para el entrenamiento del algoritmo seleccionado
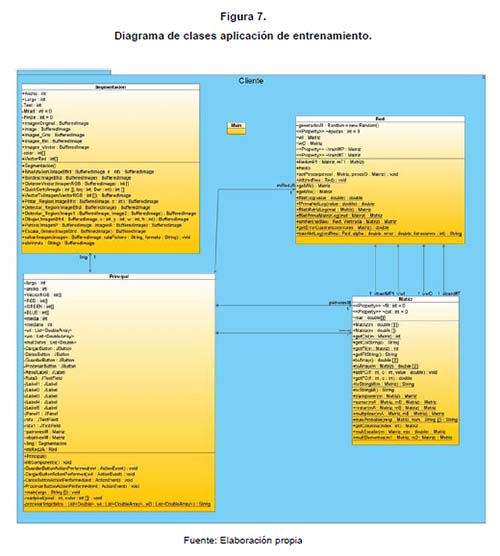
El entrenamiento consta de los datos de entrada configurados en el promedio y la mediana de la matriz G de la imagen RGB y una matriz objetivo establecida previamente a partir de los ejercicios de clasificación visual realizado por un experto y comparados con los patrones de salida de la red (figura 7).
Así es como tenemos un conjunto de datos de entrada y unos valores de salida (tabla 5).
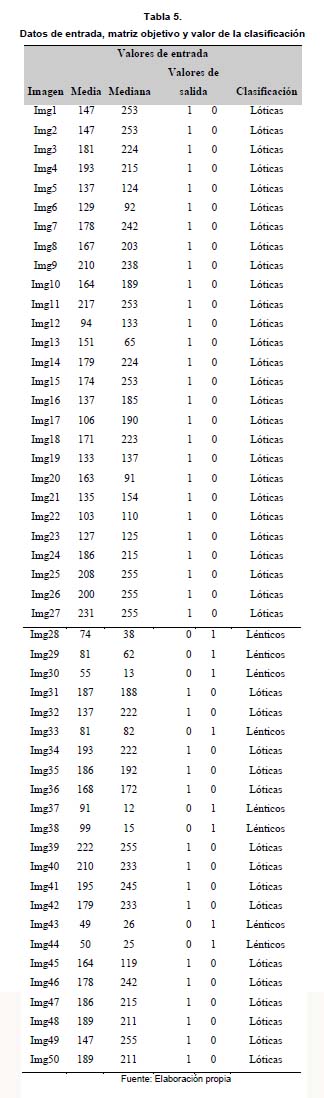
Realizando el entrenamiento se obtuvo un factor de aprendizaje de 5, un error mínimo por patrón de 1 % con 2345 iteraciones, alcanzando un error global de 6.97 %, esto permitirá dar como resultados el conjunto de los wi y wo de la red neuronal, los cuales se usaron para iniciar la red neuronal en el servicio.
Desarrollo del servicio aplicándolo a un caso de estudio: colección digital de imágenes de ecosistemas amazónicos
Una vez obtenidos los valores de los wi y los wo en el proceso de entrenamiento, se realizará una adaptación del algoritmo de la red neuronal para poder recibir de forma masiva la información de las imágenes ya procesadas; utilizando la aplicación mencionada se puede obtener el conjunto de los valores para ser ingresados a la red.
Para lo anterior se construyó un servicio web en Java a través de un proyecto web realizado en el IDE de NetBeans y una aplicación cliente por medio de la cual se puede consumir el servicio; para esto se generó el esquema y el archivo WSDL.
Procedimiento para la construcción del ambiente en la nube
A través de una cuenta de correo electrónico se realiza la inscripción en Amazon para acceder a los servicios en la nube; una vez ahí se despliega la aplicación en un servidor apache con el servicio de 8 en la consola de aws archivo .war desplegado previamente en el IDE de NetBeans (figura 8).
Una vez cargado el archivo, se procede a realizar el despliegue para poder usar la aplicación desde la nube (figura 9).
Luego de cargada la aplicación, verificamos que el dominio está en uso y que se puede acceder desde cualquier navegador.
Desarrollo del cliente en Android
Utilizando el IDE de eclipse para desarrollar aplicaciones Android, construimos el software para móviles que consumirá el servicio de clasificación, para ello se realizó una interfaz gráfica para capturar imágenes, ya sea a través de la cámara del dispositivo o cargar imágenes de la galería para luego preprocesarlas y conseguir la matriz de muestras (figura 10).
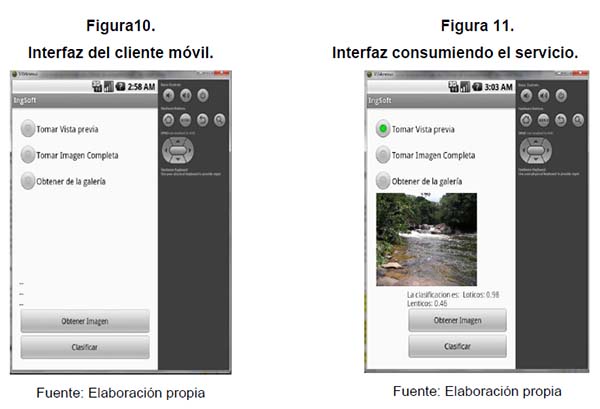
Una vez tomada la imagen o cargada de la galería de imágenes del dispositivo, se procede a clasificarla. Para lo cual el usuario debe activar el botón de clasificación con el fin de el algoritmo proceda a descomponer la imagen, obtener la media y la mediana de la muestra y enviar estos valores a través del método clasificar del servicio web, transmitiendo estos valores al servidor y a la red neuronal que está en la aplicación retornando el valor de la clasificación.
Como se puede observar en la figura 10, el servicio clasifica la imagen en este caso como lóticos en un porcentaje de 0.98 y como léntico 0.46, por lo cual se puede manifestar que esta imagen es de un ecosistema lótico o de agua corriente.
Conclusiones
Se determinó que a partir de los autores estudiados no hay un modelo de clasificación que use la nube para determinar los estados de las colecciones de imágenes digitales de ecosistemas acuáticos amazónicos usando una técnica, como las redes neuronales.
Se pueden aplicar servicios web a todos los procesos de clasificación en los diferentes niveles de la tabla para intercambiar entre servicios la clasificación.
Se puede liberar la aplicación a los usuarios de teléfono celular con sistema operativo Android para ayudar a clasificar todos los ecosistemas que se encuentran en el piedemonte amazónico, y de esta forma contribuir a la recolección de la información de la Amazonía continental.
El desarrollo de los servicios web se puede implementar en sistemas ya creados; solo es necesario realizar la interfaz de servicio.
Se puede entrenar la red neuronal en trabajos futuros para que clasifique otros elementos hídricos en el sistema ambiental.
El tiempo que consume es mínimo en relación con otras aplicaciones de clasificación; esto se debe a su pre +procesamiento que realiza el móvil antes de enviar los parámetros a la red neuronal.
Referencias bibliográficas
Gobernación de Caquetá (2008). Plan departamental de desarrollo 2008-2011. Ordenanza No. 008 de 28 de mayo de 2008.
Duivenvorden, J. F. y Lips, H. (1993). Ecología del paisaje del medio Caquetá. En J. Saldarriaga y T. Vander Hammen (eds.), Estudios de la Amazonía Colombiana, 3.
Universidad de la Amazonia (2011). Vicerrectoría de Investigaciones y Posgrados.
Pajares Martinsanz, G. (2002). Visión por computador. Imágenes digitales y aplicaciones. México: Alfaomega.
Amazon.com (2013, agosto). Amazon web service. Recuperado de http://aws.amazon.com/es/careers/ Visual-paradigm.com (2013, agosto). Express UML tool. Recuperado de http://www. visual-paradigm.com/ Código (2013). Aplicaciones de redes neuronales en JAVA. Recuperado de http://pabloborbon.com/2010/03 /aplicación -de-redes-neuronales-en-java/
Martínez F., Díaz M. C., Martín M. T., Rivas, V. M. y Ureña, L. A. (2009). Aplicación de redes neuronales y redes bayesianas en la detección de multipalabras para tareas IR. Jaén: Universidad de Jaén.
License
When submitting their article to the Scientific Journal, the author(s) certifies that their manuscript has not been, nor will it be, presented or published in any other scientific journal.
Within the editorial policies established for the Scientific Journal, costs are not established at any stage of the editorial process, the submission of articles, the editing, publication and subsequent downloading of the contents is free of charge, since the journal is a non-profit academic publication. profit.

