DOI:
https://doi.org/10.14483/udistrital.jour.reving.2017.1.a07Publicado:
2017-01-30Número:
Vol. 22 Núm. 1 (2017): Enero - AbrilSección:
Ingeniería de SistemasUna Mirada a la Web de los Datos. Caso de Estudio: Consumo de Servicios CKAN
A View of the Web of Data. Case Study: Use of Services CKAN
Palabras clave:
CKAN, Web de Datos, DataHub, JSON, Linked Data. (es).Palabras clave:
CKAN, Web of Data, DataHub, JSON, Linked Data (en).Descargas
Referencias
T. Berners-Lee, C. Bizer, T. Heath. (Enero, 2009) «Linked data-the story so far». International Journal on Semantic Web and Information Systems, vol. 5, pp. 1-22, 2009.
S. Dietze, H. Yu, D. Giordano, E. Kaldouidi, N. Dovrolis, D. Taivi. (Marzo, 2012) «Linked Education: Interlinking Educational Resources and the Web of Data,» 27th annual ACM symposium on Aapplied Computing, pp. 366-371, 2012. [Online]. Available: http://oro.open.ac.uk/31077/. [Último acceso: 2016 Abril 28].
B. Haslhofer, A. Isaac (2011). «Data. europeana. eu: The europeana linked open data pilot» International Conference on Dublin Core and Metadata Applications, pp. 94-104, 2011. [Online]. Available: http://dcpapers.dublincore.org/pubs/article/view/3625/1851. [Último acceso: 25 de Abril de 2016].
D’Aquin, M. et al. (Junio, 2014) «Building the Open Elements of an Open Data Competition» D-Lib Magazine, vol. 20, p. 3, 2014. [Online]. Available: http://www.dlib.org/dlib/may14/daquin/05daquin.html. [Último acceso: 28 de Abril de 2016].
L. Project. (Diciembre, 2014). «Linking Web Data for Education». [En línea]. Available: http://linkedup-project.eu/. [Último acceso: 27 Abril 2016].
G. Klyne, J. Carroll (2006). «Resource description framework (RDF): Concepts and abstract syntax» 2006. Edited by Brian Mcbride. [Online]. Available: http://www.citeulike.org/group/2170/article/532408. [Último acceso: 2016 Abril 28].
M. Hausenblas. (Julio, 2009). «Exploiting linked data to build web applications» IEEE Internet Computing, vol. 13, nº 4, p. 68. 2009.
S. Auer, C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak, Z. Ives (2007). «DBpedia: A Nucleus for a Web of Open Data» de The Semantic Web, Busan, Korea, Springer, 2007.
LOD-Cloud. (s.f.). «The Linking Open Data Cloud Diagram» [Online]. Available: http://lod-cloud.net/. [Último acceso: 27 Abril 2016].
DataHub. (s.f.). «DataHub Project» [Online]. Available: http://datahub.io/dataset?tags=lod. [Último acceso: 27 Abril 2016].
Ministerio de Hacienda y Administración Pública - Ministerio de Industria Energía y Turismo, (Febrero, 2015.) «Plataformas de Publicación de Datos Abiertos» [En línea]. Available: http://datos.gob.es/sites/default/files/informe-herramientas-publicacion.pdf. [Último acceso: 30 Abril 2016].
OKF, (s.f.) «Open Knowledge Foundation» [En línea]. Available: http://services.okfn.org/. [Último acceso: 25 Abril 2016].
CKAN, (s.f.). «The Open Source Data Portal Software,» [En línea]. Available: http://ckan.org/. [Último acceso: 20 Abril 2016].
CKAN. (s.f.). «API Guide - CKAN’s API for developers,» [En línea]. Available: http://docs.ckan.org/en/latest/api/index.html. [Último acceso: 21 Abril 2016].
CKAN. (s.f.) «Ckan Wiki - CKAN Pages,» [En línea]. Available: https://github.com/ckan/ckan/wiki/_pages. [Último acceso: 23 Abril 2016].
J. Wonderlich. (Agosto, 2010). «Ten principles for opening up government information,» [En línea]. Available: http://sunlightfoundation.com/policy/documents/ten-open-data-principles/. [Último acceso: 15 Abril 2016].
CKAN. (s.f.). «CKAN API Guide» [En línea]. Available: http://docs.ckan.org/en/latest/api/. [Último acceso: 31 Mayo 2016].
J. Winn. (Mayo, 2013). «Open data and the academy: an evaluation of CKAN for research data management. (IASSIST 2013)». 28-31 Mayo 2013. [En línea]. Available: http://eprints.lincoln.ac.uk/9778/1/CKANEvaluation.pdf. [Último acceso: 31 Mayo 2016].
E. Rajabi, S. Sanchez-Alonso, M.-A. Sicilia. (Abril, 2014). «Analyzing broken links on the web of data: An experiment with DBpedia» Journal of the Association for Information Science and Technology. vol. 65, nº 8, p. 1721–1727, 2014. [Onine]. Available: http://onlinelibrary.wiley.com/doi/10.1002/asi.23109/abstract. [Último acceso: 31 Mayo 2016].
C. Bizer. (Octubr, 2009). «The Emerging Web of Linked Data». IEEE Intelligent Systems, vol. 24, nº 5, pp. 87-92, 2009. [Onine]. Available: http://lpis.csd.auth.gr/mtpx/sw/material/IEEE-IS/IS-24-5.pdf. [Último acceso: 31 Mayo 2016].
HPI Institut. (Septiembre, 2011). «State of LOD Cloud,» [En línea]. Available: http://lod-cloud.net/state/. [Último acceso: 26 Marzo 2016].
M. Allison, S. Richard, K. Patten, C. Caudill-Daugherty, A. Anderson. (Abril, 2015). «Open Access to Geoscience Data for Exploration and Assessment». 19 al 25 Abril 2015. [En línea]. Available: http://www.geothermal-energy.org/pdf/IGAstandard/WGC/2015/33032.pdf. [Último acceso: 27 Abril 2016].
W. Mao, J. Jan. (Octubre, 2015). «Visualization of Open Data: A CaseStudy of Climate Data». 36 Asian Conference on Remote Sensing. 19-23 de Octubre de 2015. Manila, Philippines. [En línea]. Available: http://www.acrs2015.org/list-of-accepted-abstracts/. [Último acceso: 4 Septiembre de 2016].
R. Carvalho, J. Aguiar, J. Rocha, C. Ribeiro. (Junio, 2016). «A comparision of research data management platforms: architecture, flexible metadata and interoperability» Junio de 2016. [En línea]. Available: https://www.researchgate.net/publication/303918099_A_comparison_of_research_data_management_platforms_architecture_flexible_metadata_and_interoperability. [Último acceso: 1 Septiembre 2016].
CURE. «Infraestructura semantica basada en el paradigma de datos abiertos para la gestion de investigacion de las Universidades españolas». (2016). CRUE Universidades Españolas. 2016. [En línea]. Available: http://tic.crue.org/wp-content/uploads/2016/07/Memoria-proyecto-H%C3%A9rcules.pdf. [Último acceso: 2 Septiembre 2016].
Datos.gob.es. (s.f.). «Estudio de Plataformas tecnologicas datos.gob.es». Ministerio de Industria, Turismo y Comercio. [En línea]. Available: http://datos.gob.es/sites/default/files/files/2_cms_01.pdf. [Último acceso: 2 Septiembre 2016].
P.A. Gaona-García, C. E. Montenegro., & H.W. Gonzalez, (2014) «Hacia una Propuesta de Mecanismos para la Autenticidad de Objetos de Aprendizaje en Plataformas LCMS». Ingeniería, Vol. 19, nº 1, p. 50 –64
Cómo citar
APA
ACM
ACS
ABNT
Chicago
Harvard
IEEE
MLA
Turabian
Vancouver
Descargar cita
DOI: http://dx.doi.org/10.14483/udistrital.jour.reving.2017.1.a07
Una Mirada a la Web de los Datos. Caso de Estudio: Consumo de Servicios CKAN
A View of the Web of Data. Case Study: Use of Services CKAN
Jhon Francined Herrera-Cubides
Universidad Distrital Francisco José de Caldas- Facultad de Ingeniería-Bogotá, Colombia.:jfherrerac@udistrital.edu.co
Paulo Alonso Gaona-García
Universidad Distrital Francisco José de Caldas- Facultad de Ingeniería-Bogotá, Colombia.:jfherrerac@udistrital.edu.co
Kevin Gordillo Orjuela
Universidad Distrital Francisco José de Caldas- Facultad de Ingeniería-Bogotá, Colombia.:jfherrerac@udistrital.edu.co
Recibido: 05-07-2016. Modificado: 05-09-2016. Aceptado: 12-10-2016.
Resumen
Contexto: Se busca llevar a cabo el análisis, conexión y uso de los servicios ofrecidos por Comprehensive Knowledge Archive Network (CKAN, por sus siglas en inglés), con el fin de evaluar criterios base para obtener referentes preliminares de estudio sobre el estado de la web de los datos, a través de la exploración y acceso de los dataset publicados en el repositorio de datos abiertos DataHub.io.
Método:Empleamos los servicios ofrecidos por CKAN para la consulta y descarga de los dataset publicados en Datahub.io, para lo cual presentamos una serie de procesos llevados a cabo para analizar los datos descargados. La propuesta se compone de tres actividades clave: (1) revisión y análisis de las plataformas; (2) configuración y uso de los servicios prestados por la API; y (3) descarga y revisión de la información obtenida.
Resultados: Se configuraron y desplegaron los servicios requeridos, a través de CKAN, con el fin de llevar a cabo las consultas y descargas respectivas de dataset. Se procesó y analizó la información obtenida de los JSON descargados, permitiendo hacer un análisis preliminar comparativo, de la información obtenida acerca del comportamiento de la web de los datos.
Conclusiones: CKAN es una herramienta potente para gestionar catálogos de datos, permitiendo manejar una descripción de los datos y otra información relevante, tanto para las organizaciones que publican como para las personas que consultan dicha información, tales como categorías de organizaciones, formatos en que se encuentra disponible los datos, propietario de los datos, el tipo de licenciamiento de las publicaciones, enlaces a otros datos, entre otros datos, pertinentes para llevar a cabo un análisis de la web de los datos.
Palabras clave: CKAN, Datahub, JSON, Linked Data, web de datos.
Idioma: Español.
Abstract
Context: In order to assess basic criteria so as to obtain preliminary guidelines on the current state of the Web of Data, we analyze the connection and use of the services offered by CKAN - Comprehensive Knowledge Archive Network; the analysis is conducted through exploration and connection to datasets published in the datahub.io open data repository.
Method: We use the services offered by CKAN for consultation and downloading datasets published in Datahub.io, we propose a procedure carried out to analyze the downloaded data. The proposal consists of three key activities: (1) review and analysis of platform, (2) Setting up and using the services provided by the API and (3) download and review of the information obtained.
Results: The required services offered by the platform CKAN were configured and deployed, in order to carry out queries and downloads related to each dataset. The obtained information was processed and analyzed from the downloaded JSON, allowing a comparative preliminary analysis of the information regarding the behavior of the Web of Data.
Conclusions: CKAN is a powerful tool to manage data catalogs. This tool can handle a description of the data and other relevant information, from organizations that publish to people who query such information. These queries provide information as categories of organizations, data formats and owners, the type of publication licenses, links to other data, among other which are relevant to perform an analysis of the Web data.
Keywords: CKAN, Web of Data, DataHub, JSON, Linked Data.
1. Introducción
La iniciativa propuesta por Tim Berners Lee [1] asociados a la vinculación de datos mediante Linked Data promete resolver los problemas asociados con el análisis y la interoperabilidad de los datos vinculados a recursos relacionados. En la actualidad existen varios ejemplos que permiten el uso de datos vinculados en diferentes áreas de conocimiento tales como la medicina, la geografía, la bibliotecología, entre otras. Por ejemplo, en el campo de la educación, la vinculación de los recursos educativos de diferentes repositorios de conocimiento es útil en la Web, permite el intercambio, la búsqueda y la navegación de objetos de aprendizaje [2]. Varios proyectos como Europeana [3], LinkedUp [4], [5]:, y Linked Education [2], han adoptado el enfoque de Linked Data y su objetivo responde a vincular conjuntos de datos educativos.
Por su parte, el proyecto Linked Open Data (LOD, por sus siglas en inglés) es otra iniciativa orientada a aplicar los principios de la web semántica con el fin de conectar recursos. LOD utiliza tecnologías como Resource Description Framework (RDF, por sus siglas en inglés) [6] y Uniform Resource Identifier (URI, por sus siglas en inglés), junto con un conjunto de principios denominados “datos vinculados”. Varias fuentes de datos, como Wikipedia, están ahora disponibles para los desarrolladores, que claramente se benefician de los conjuntos de datos vinculados con base en un modelo de datos común [3].
Datahub, sujeto de aná;lisis en el presente artículo, es una plataforma para la gestión de datos, basada en CKAN - Comprehensive Knowledge Archive Network [17] - [18], que es una herramienta para la gestión y publicación de colecciones de datos (Datasets) en un ambiente web, utilizado por diferentes gobiernos, nacionales y locales, instituciones de investigación, entre otras (denominadas “organizaciones” en CKAN), que recogen una gran cantidad de datos. A través de sus servicios, los usuarios pueden buscar y encontrar los datos que necesitan.
La motivación de este trabajo es presentar, a través de un estudio de caso basado en Datahub, como a partir de la conexión y el consumo de datos que pueda ofrecer el Application Programming Interface (API, por sus siglas en inglés), en este caso CKAN [17], se pueden obtener variables para la realización de un análisis preliminar sobre la visión de la web de los datos. Dicho caso estudio busca propiciar herramientas, para la identificación de tendencias en el modelo de la web de los datos, tomando como base datos históricos presentes en Datahub.io, como plataforma de gestión de datos, en el marco del proyecto de investigación sobre vinculación de datos que se viene adelantando.
El resto del siguiente artículo se encuentra organizado de la siguiente manera: en la primera parte de se encuentra el estado del arte, donde se revisan los fundamentos de la temática explorada. Posteriormente, en la sección III se presenta el planteamiento metodológico utilizado para la exploración de los conjuntos de datos. En la sección IV, se presenta el desarrollo metodológico, junto con los hallazgos encontrados, en la sección V se presenta el análisis de resultados. Finalmente, en la sección VI se presentan las conclusiones y trabajo futuros.
2. Estado del arte
Gracias al modelo de web de los datos, varias fuentes de datos, como Wikipedia, están ahora disponibles para los desarrolladores, que claramente se benefician de los conjuntos de datos vinculados con base en un modelo de datos común [7]. Por su parte, el proyecto DBpedia [8] dispone de un conjunto de datos que actualmente se consideran como el eje central y más significativo entre los conjuntos de datos LOD [9]. En la web se encuentran iniciativas LOD tales como las plataformas de gestión de datos, entre ellas:
- Datahub (https://datahub.io/), objeto de examen en este artículo, la cual permite buscar y publicar datos, crear y gestionar grupos de Dataset, entre otras funcionalidades [10].
- Junar (http://junar.com/), plataforma de datos abiertos en la nube que facilita la publicación de datos por parte de gobiernos, empresas u otras organizaciones [11].
- Socrata (https://www.socrata.com/), plataforma escalable de publicación de datos en la nube que facilita la creación de iniciativas de datos abiertos sostenibles, ofreciendo un amplio conjunto de funcionalidades [11].
- data.gov.uk To Go (http://guidance.data.gov.uk/), kit del gobierno de Reino Unido para poner a disposicion del público en general, su plataforma de publicación de datos de forma que cualquiera pueda desplegar una plataforma similar, preocupándose únicamente de adaptar la apariencia externa final [11].
- Plataforma de Gobierno Abierto OGoov (http://www.ogoov.com/es/), ofrece una serie de funcionalidades combinables entre si según la orientación o iniciativas relacionadas con el gobierno abierto que se deseen priorizar: datos abiertos, transparencia y participación [11].
Estas entre otras plataformas, han permitido una mayor visibilidad de datos compartidos y han facilitado la participación de iniciativas como LOD Cloud [9], para la visualización de las organizaciones y proveedores de contenidos que han liberado y enlazado sus datos.
Como parte de un proyecto de investigación de tesis doctoral en curso, orientado en el dominio de la vinculación de datos, se plantea recabar información preliminar sobre el contenido de la nube LOD a 2016. Con tal fin, y dado que en experiencias como [9] donde se trabajó con DBPedia, para el presente estudio se propone analizar la plataforma de gestión de datos libres Datahub.io, de la Open Knowledge Foundation [12] – OKFN. Esta fundación tiene como visión que el conocimiento crea poder para muchos, no para unos pocos, los datos nos libera para tomar decisiones informadas sobre la forma en que vivimos, lo que compramos y quien recibe nuestro voto; la información y el conocimiento son accesibles, aparentemente, a todo el mundo. Por otra parte, Datahub.io, como una de las plataformas de gestión de datos y repositorio internacional de datos abiertos reconocidas [25], es una de las que más Dataset aporta a la conformación del Linked Open Data Cloud Diagram [9].
CKAN maneja un backend construido en Python, y un frontend construido en JavaScript. También usa el framework web Pylons y SQLAlchemy como ORM, con PostgreSQL como motor de base de datos. Tiene una arquitectura modular que permite desarrollar extensiones para proporcionar características adicionales, tales como harvesting o carga de datos, visualización de múltiples vistas, diferentes extensiones, un JSON API para leer, escribir y hacer consultas a los Dataset, soportado en más de 40 lenguajes, entre otras funcionalidades [ 23] - [24].
Al ser de código abierto, licenciado bajo términos GPL v3.0 Affero GNU, los usuarios CKAN pueden adaptar sus servicios, como lo han hecho, entre otros [13]:
- Africa's Largest Volunteer Driven Open Data Platform (https://africaopendata.org/).
- data.amsterdam.nl (http://data.amsterdam.nl/).
- Buenos Aires Data (http://data.buenosaires.gob.ar/).
- Paraguay Digital (https://www.datos.gov.py/).
- La plataforma cívica de datos abiertos de México (http://datamx.io/).
- Registro de conjuntos de datos abiertos en Noruega (http://data.norge.no/ ).
Ahora bien, para los propósitos de CKAN, los datos se publican en unidades denominadas “Data- Set”. Un Dataset es un paquete de datos -por ejemplo, podría ser las estadísticas de la delincuencia para una región, las cifras de gasto para un departamento gubernamental o las lecturas de temperatura de varias estaciones meteorológicas-. Cuando los usuarios buscan datos, los resultados de búsqueda que se obtiene son Dataset individuales. Un Dataset contiene dos componentes [13]:
- Información o “metadatos”sobre los datos. Estos datos deben proveer la siguiente información:
- Título, unico a través de CKAN, de modo que sea breve pero específica. Por ejemplo: “densidad de población del Reino Unido según la región. Es mejor que “Las cifras de población”.
- Descripción, información que la gente necesita saber cuándo se utilizan los datos.
- Etiquetas, etiquetas que ayuden a la gente a encontrar los datos y la vinculan con otros datos relacionados.
- Licencia, información de la licencia para que se sepa cómo se pueden utilizar los datos.
- Organización, elegir quien es el propietario del Dataset.
- Un número de “recursos” , que contienen los datos en sí. CKAN no le importa en que formato están los datos (hoja de cálculo CSV (comma-separated values) o Excel, XML, PDF, archivo de imagen, RDF, entre otros). CKAN puede almacenar el recurso internamente o almacenar un enlace al recurso en sí, ubicado en otra parte en la web. Para los recursos se debe proveer la siguiente información:
- Nombre, un nombre para el recurso.
- Descripción, una breve descripción del recurso.
- Formato, el formato de archivo del recurso, por ejemplo, CSV, XLS, JSON (JavaScript Object Notation), PDF, etc.
- Visibilidad, un Dataset público puede ser visto por cualquier usuario del sitio. Un Da taset privado solo puede ser visto por los miembros de la organización propietaria del Dataset y no se mostrará en las búsquedas realizadas por otros usuarios.
- Autor, el nombre de la persona u organización responsable de la producción de los datos.
- Correo electrónico del autor.
- Correo electrónico del responsable de mantenimiento.
- Campos personalizados, si desea adicionar más datos.
Considerando lo anteriormente descrito, en Datahub.io, se registra 822 organizaciones (propietarios de los Dataset), creadas con previa autorización de un administrador, a través del envío de una solicitud. Estas organizaciones pueden crear, administrar y publicar colecciones de conjuntos de datos y pueden tener miembros tales como administradores (que añaden usuarios y gestionan la organización), y editores (que solo pueden añadir conjuntos de datos de la organización). Dicha distribución en organizaciones provee las siguientes características:
- Se proporciona una estructura de permisos y autorizaciones mucho más rica (en torno a la organización), que ofrece a los usuarios un mayor control sobre quién puede o no, editar y añadir conjuntos de datos.
- Proporciona una estructura orientada a la organización, para la presentación y la búsqueda de bases de datos.
- Ayuda a controlar problemas de spam, proporcionando más control sobre quién añade conjuntos de datos.
Dentro de las organizaciones incluidas en Datahub.io se encuentran las que se presentan en la tabla I, junto con el total de Dataset publicados por cada una de ellas.
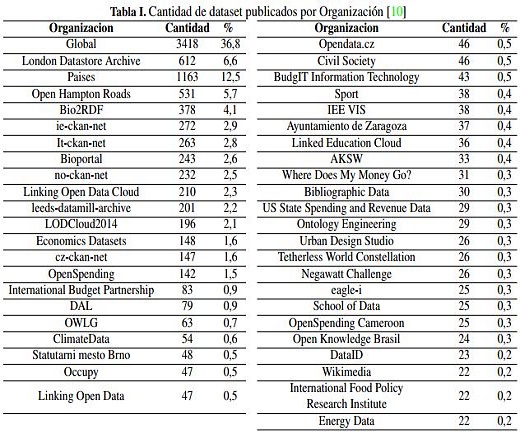
Como se observa en la tabla I, la categoría “Global” es la que maneja la mayoría de Dataset publicados. Lo anterior se debe al proceso de migración realizado por la plataforma, dejando en esta categoría a aquellos Dataset que no eran parte de ninguna organización. Por otro lado, se observa que la siguiente categoría de mayor publicación es la correspondiente a “países”. De igual forma, en Datahub.io se encuentran publicados 10.900 Dataset.
Es importante anotar que hay organizaciones que:
- No tienen ningún Dataset publicado.
- Tiene un archivo de prueba de carga, que no configurar ning&uaucte;n tipo de Dataset.
- Tiene uno o más de un Dataset publicado, en diferentes formatos (que van desde CSV hasta PDF; XML, Sparql - SPARQL Protocol and RDF Query Language, etc.), y con diferentes tipos de licenciamiento.
- Tiene publicados otros archivos diferentes a un Dataset.
Dentro de la literatura se encuentran algunos trabajos relacionados tales como [19], quienes describen el problema de los enlaces abiertos y la estrategia para resolver este problema. Por su parte, en [20] se muestra las cantidades de datos vinculados disponibles a partir de julio de 2009 y el número de enlaces entre conjuntos de datos RDF; y en [21] se presenta un estudio de estadísticas acerca de la estructura y contenido de la nube LOD.
Es así como a partir de este panorama, el siguiente documento tiene como propósito presentar un estudio de caso sobre la configuración, acceso y consumo de datos que pueda ofrecer el API CKAN [17], con el fin de poder consultar una muestra de los Dataset publicados en Datahub, seleccionados de forma aleatoria, con los cuales se podrá identificar y extrapolar, de manera preliminar , las tendencia del modelo de la web de los datos a partir de los datos históricos presentes en Datahub.io, como plataforma de gestión de datos. Análisis que se plantea en etapas posteriores del proyecto que enmarca esta investigación. El motivo de usar esta API se debe a que CKAN está escrito en Python y hace uso de una variedad de framework de código abierto, incluido Pylons, el cual es una combinación de varios framework de código abierto integrados que forman la base para aplicaciones de nivel empresarial basados en la web.
El almacenamiento y gestión de datos de CAKN incluye el almacenamiento de archivos, gestión de metadatos, y la gestión de datos estructurados. Ademas, ofrece un mecanismo de plug-in, que permite a los desarrolladores extender rápidamente la funcionalidad de CKAN. De igual forma, CKAN posee la capacidad de soportar características geográficas, así como la exposición de metadatos de acuerdo con el catálogo estándar Open Geospatial Consortium (OGC, por sus siglas en ingles) y Catalog Service for the Web (CSW, por sus siglas en inglés). Por último, CKAN implementa funciones de limpieza cruciales tales como el logueo y gestión de usuarios [22].
3. Planteamiento metodológico
Para llevar a cabo el proceso de conexión y descarga de los Dataset publicados en Datahub.io, se realizaron una serie de actividades tal como se describe en la figura 1.
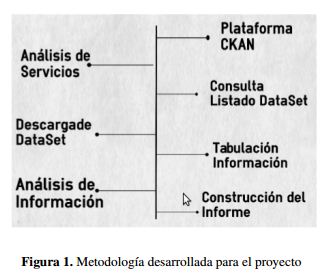
Tal como se presenta en la figura 1 las actividades mas relevantes son:
- Se revisó la plataforma CKAN, con el fin de establecer los servicios que ésta provee, al igual que la forma de acceder a ellos. Para esta labor se hizo uso del CKAN's API guide [14]- [15].
- Posteriormente se estudió la forma de conectarse a los servicios prestados por CKAN, con el fin de descargar los Dataset publicados en Datahub.io [14]-[15].
- Haciendo uso de los servicios de CKAN, se consultó el listado de los nombres de los Dataset publicados.
- Dada la cantidad de Dataset publicados, Datahub usa la estrategia de publicar grupos de Dataset (en sus respectivos formatos) por páginas, para un total de 545 páginas. Teniendo en cuento la distribución anterior, se descargaron archivos JSON, formato de archivo que se descarga localmente, los cuales contienen los Dataset publicados por página en la plataforma de gestión de datos.
- Por último, con el fin de revisar la integridad de la descarga, se llevó a cabo un análisis comparativo de la información, haciendo uso de herramientas que permitieran visualizar la data descargada, con la revisión manual de algunos Dataset publicados.
- Construcción del presente artículo, de acuerdo a los resultados obtenidos.
4. Materiales y métodos
Dado que el presente documento se basa en la descripción de un caso de estudio acerca de la conexión y consumo de los servicios ofrecidos por CKAN y, con el fin de que el procedimiento seguido pueda ser replicado a posteriori, a continuación se describen el proceso desarrollado con el fin de poder consumir los servicios del API, y por ende consultar los Dataset, dispuestos en paginas, para posteriormente ser descargados en archivos JSON, los cuales permitirán llevar a cabo un análisis preliminar de las tendencias del modelo de la web de los datos. El proceso seguido, junto con los recursos necesarios para la conexión y consumo se describe a continuación.
4.1. Recursos para la conexión a Datahub.io – CKAN API:
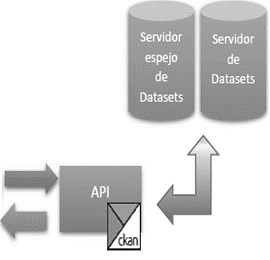
Datahub.io, como sitio desarrollado usando la API de CKAN, permite hacer uso de las funcionalidades que provee la API como consultar los metadatos (información acerca del dato alojado), descargar la lista de los Dataset alojados, información de organizaciones, etiquetas que identifican determinado Dataset, entre otras funciones.
El proceso para realizar consultas sobre la API plantea el uso de los siguientes recursos (Tabla II).

La figura 2 se muestra la interacción de los recursos necesarios para conectarse a los servicios de CKAN.
4.2. Proceso de instalación y consulta al API:
Instalacion HTTPie: una vez ubicado en el entorno Ubuntu, se procede a abrir una terminal y ejecutar el comando:
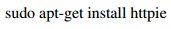
La figura 3 muestra los resultados de la ejecución del citado comando
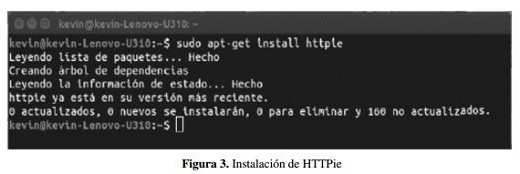
Una vez ha terminado el proceso de instalación, ya se pueden realizar peticiones a servidores http, en este caso CKAN. La documentación de HTTpie se puede encontrar en el repositorio https://github.com/jkbrzt/httpie.
Ahora bien, la estructura basica para una consulta HTTPie se formula de la siguiente manera:
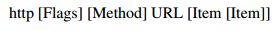
Consulta de los DataSet: CKAN provee métodos para consultar los repositorios del sitio que ha sido desarrollado con su API. Para hacer uso de dichos métodos basta con agregar al sitio principal (que haga uso de CKAN) la sintaxis:
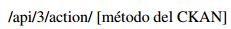
Con el fin de aclarar lo descrito anteriormente, se hará una consulta a Datahub.io de todos los nombres de los Dataset que tiene y, por defecto, el servidor devolverá el resultado en una lista con estructura tipo JSON. Para realizar este proceso se abre una terminal y se digita:
La figura 4 muestra los resultados de la ejecución del citado comando.
Seguido a esta ejecución, se desplegará dentro de la misma consola los nombres de todos los Dataset de Datahub.io. Si adicionalmente se quiere descargar la información consultada y volcarla a un archivo, se debe agregar las banderas --download y -o, incluidas en HTTpie. La bandera --download permite descargar el archivo; y la bandera o permite nombrar y ubicar el archivo descargado. Por ejemplo, para descargar la lista anterior se realiza el proceso descrito en la figura 5.
Como resultado de esta ejecucion se descarga el archivo con el nombre “lista_Datasets.json”, en el folder “Ejemplo”, previamente creado.
Por otro lado, para descargar todos los Dataset de Datahub.io, se puede hacer uso del método current package list with resources. Sin embargo, este método solo descarga de a diez Dataset si no se le especifica algún tipo de parámetro. Adicionalmente, su capacidad máxima de descarga de Dataset es de 1000, es decir que el archivo de descarga tendrá como máximo 1000 Dataset. Por ende, para descargar los Dataset publicados en la plataforma se escribe un script en Python, que haga uso de un ciclo for, que permita descargar los Dataset completos de cada página hasta completar 535 páginas. En la figura 6 se muestra el script y el resultado de su ejecución.
Para ejecutar el script desde la terminal, se debe ubicar en el directorio donde se va a guardar el archivo y se ejecuta el comando Python [Nombre del archivo], que para este caso corresponde: Python script.py
El resultado de la iteración es la generación de un archivo por página (535 archivos), como se muestra en la figura 7.
5. Resultados y discusión
Como primer resultado obtenido en el proceso de conexión, se descargó el listado de Dataset publicados en la plataforma. La figura 8 muestra, al costado derecho el archivo JSON resultante de la consulta y al costado izquierdo el árbol de consulta resultante, donde cada valor de arreglo “result” corresponde a un nombre de Dataset consultado.

En total se obtuvieron 10694 entradas a la variable “result”, que representa la misma cantidad de nombres de Dataset consultados.
Posterior a esta consulta, se procedió a la descarga del listado de Dataset, como se especificó en la sección de Métodos y Materiales, generando 545 archivos correspondientes al mismo número de páginas existentes en la plataforma. Con este producto obtenido, se procedió a comparar y verificar la información resultante del proceso de descarga.
- DataSet consultado en la plataforma de Datahub.io: para revisar manualmente el proceso se tomo como ejemplo y punto de referencia la Organización “Listed Indian Companies”, la cual tiene un Dataset publicado en dos formatos, como se observa en la figura 9.
- En la figura 10 se observa el segmento del archivo JSON, que contiene la informació de esta organización.
- Haciendo uso de herramientas visualizadoras de archivos JSON, se puede revisar la información contenida en el segmento JSON, tal como los muestran las figuras 11 y 12.
- De igual forma, con este tipo de herramientas se pueden revisar parámetros de evaluación, tales como tipo de licenciamiento, ultima fecha de actualización, tipo de formatos publicados, entre otros que pueden brindar información relevante al momento de evaluar el estado de la web de los datos. La figura 13 permiten evidenciar la información brindada por este tipo de herramientas.
- Para la realización de un análisis preliminar de la información descargada, se seleccionó, de forma aleatoria, una muestra de 54 organizaciones y se procedió a revisar los Dataset publicados, 311 en total, con el fin de levantar la información acerca de dominios, formatos licenciamiento y última fecha de publicación de los Dataset.



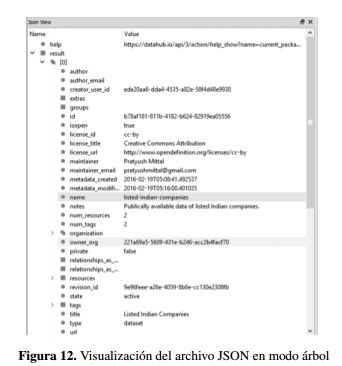

Como se observa en la figura 13, el Dataset consultado como ejemplo de verificación, tiene dos recursos publicados: BSE Companies y NSE Companies, ambos en formato CSV, bajo licencia cc-by, con fecha de última actualización el 19 de febrero de 2016.
Como resultado de este proceso se obtuvo la siguiente información:
- Dominio de Datos: En los 311 Dataset revisados, en la figura 14 se categorizan los dominios de la siguiente manera:
- Ciencia, con un 23 %, en la cual los mayores subdominios son arqueología, química y bioinformática.
- Cultura, gobierno y web semántica, con un 14 %.
- Estadística, con un 11 %.
- Formatos de publicación: como se observa en la revisión preliminar realizada en Datahub.io (Tabla III), los DataSet estan cargados en la plataforma en diferentes formatos (algunos de las organizaciones cargan mas de un tipo de formato).
- Fecha de ultima actualización: en cuanto a la fecha de ultima actualización, teniendo en cuenta
que bajo los Principios de Open Data [16], estos datos deben ser “Actualizados”, con el fin de que
no pierdan su valor y sean precisos, como resultado de la exploración muestral realizada, se identifica
que el 1 % de los mismos alcanzaría un grado de actualización frecuente, un 7,7 % un grado de
actualización media, mientras que un 60 % presenta un grado de actualización deficiente.
En este aspecto es importante resaltar que varios de los dominios corresponden a datos estadísticos generados de periodos anteriores, los cuales no requerirían de una actualización permanente, sin embargo, esta disparidad en el proceso de actualización permite reflexionar acerca del grado de actualización de los Dataset publicados.
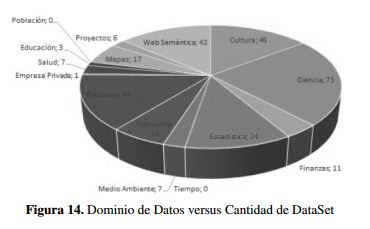
En la revisión de dominio de publicación se encuentra que los dominios de tipos de datos abiertos con mayor publicación son:
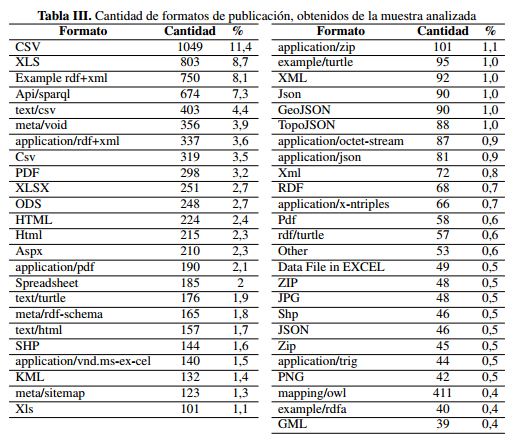
En la revisión de estos formatos, se puede observar que la plataforma no maneja un estándar unificado en cuanto a los formatos subidos, lo anterior anadido a que los formatos que se cargan no presentan una estandarización, lo que se puede observar al encontrarse como XLS, XLSX, Hoja de Cálculo, Excel, SpreedShet, MS Excel.
De igual forma, se identifica que hay publicaciones de Dataset realizadas en formatos no estructurados como PDF, PNG. Como se observa en la tabla III, en Datahub.io se pueden cargar diferentes formatos de un Dataset, encontrando por ejemplo que hay 1389 publicaciones que tiene formato de hojas de cálculo en sus formatos de publicación, lo que representa que un 13 % de los Dataset publicados y, como formatos propietarios, requieren herramientas que no son públicas.
También se identifica que varias organizaciones le han apostado a depurar sus publicaciones, escalando en el modelo propuesto por Berners-Lee [1], ofreciendo datos en formatos estructurados, abiertos al público y que permiten llevar a cabo el proceso de vinculación. Sin embargo, en este proceso tambien se observa en Datahub, situaciones como la disparidad de formatos de publicación , algunos de los cuales no permiten la interoperabilidad semántica, limitándose a la descripción sintáctica de la información o, por el contrario, publicando formatos que dificultan el procesamiento por las máquinas.
6. Conclusiones y trabajos futuros
CKAN es una herramienta potente para gestionar catalogos de datos, permitiendo manejar una descripción de los datos y otras informaciones relevantes, tanto para las organizaciones que publican como para las personas que consultan dicha información, tales como categorías de organizaciones, formatos en que se encuentra disponible los datos, propietario de los datos, el tipo de licenciamiento de las publicaciones, enlaces a otros datos.
Por otro lado, CKAN es una herramienta usada en muchos catalogos de datos abiertos, disponibles en la Web . Las organizaciones que hacen uso de CKAN, tanto privadas como públicas, publican sus datos haciendo uso de algun nivel de las recomendaciones de buenas prácticas de Open Data y las propuestas por Berners-Lee.
En cuanto a los servicios ofrecidos por CKAN, para la consulta y descarga de la data, son servicios consistentes, que ofrecen peticiones y respuestas en formato JSON, sin restricciones al público. Existen herramientas tales como Python, Java, Java, Ruby, PHP, que pueden interactuar con el API REST de CKAN, permitiendo obtener la información solicitada, la cual puede ser visualizada en diferentes formatos, haciendo uso de herramientas visualizadoras, que permiten hacer las consultas respectivas de formas más ágil.
Como lo plantea [24], es complejo seleccionar una plataforma sin realizar un estudio cuidados de las necesidades de los interesados. En el estudio citado, se plantea que CKAN se esta convirtiendo en uno de los referentes en cuanto a la gestión de catálogos de fuentes de datos, pero que a su vez presenta desventajas como el mantenimiento de una plataforma tecnológica diferente al CMS usado para gestionar los datos, falta de soporte nativo de RDF para el enriquecimiento semántico de los datos, y el despliegue de una aplicación web diferente al portal CMS usado [26].
Por su parte, Datahub.io, como plataforma de gestión de datos, permite una publicación de datos ágil, y con pocas restricciones al usuario final, a través de una interfaz web sencilla. Por otro lado, si como desarrollador o investigador, se requiere a Datahub.io, para consultar o descargar sus Dataset, ofrece una como apoyo el CKAN API, interface que interactua con diferentes herramientas, ofrece una variedad de servicios, para llevar a los procesos requeridos.
Ahora bien, dentro de las situaciones que se observan en las publicaciones realizadas en Datahub.io, corresponde a la interpretacion que algunas organizaciones en Datahub le han dado al concepto de Datos Abiertos, tomando a la plataforma como una estrategia para publicar o promocionar escritos, artículos, eventos, etc., que no poseen ningún tipo de vinculación ni de contexto ampliado a los datos expuestos. Tal es el caso de la organización 'Mente Clara', donde sus 13 publicaciones son imágenes y PDF (artículos) acerca del budismo tantrico tibetano.
Otro aspecto identificado es el acceso a ciertos recursos de los Dataset tomados como muestra, dado que las URI no accedían, generando inconvenientes para el proceso de vinculación. Este tipo de problemas podría ser causado a la falta de actualizacion de los datos publicados en la plataforma, entre otras situaciones. Independiente del origen de dicho problema, uno de los factores claves de la web de los datos es el proceso de identificación y vinculación de datos que aporten contexto al dato publicado, y la falta de enlaces resolubles afecta el desarrollo de esta tecnología.
De otro lado, en el caso de los gobiernos, por ejemplo, se identifican publicaciones que responden a los principios de transparencia y apertura de información, pero que bajo los principios de Datos Abiertos y de Linked Data, no aportan contexto a la información expuesta, limitándose a publicar listados de cuadros en hojas de cálculo, algunos de los cuales no se actualizan de forma periódica. Un ejemplo de ello es por ejemplo la organización 'Bolivia' que registra seis Datasets, en los cuales todos tiene como última fecha de actualización hace en promedio dos años, y la información contenida en ellos corresponden a tablas de hojas de cálculo de informes de indicadores sociales, que no se complementan o anaden contexto a la información, con otros enlaces o datos de interés.
Como trabajos futuros del proceso de investigación, y dados los hallazgos identificados, se plantea: 1) llevar a cabo un análisis más detallado del estado de la Web de los datos, a través de herramientas de analítica visual, 2) realizar un análisis del estado de la Web de los datos en el área de recursos digitales abiertos mediante propuestas de accesos seguros a plataformas LCMS [27], objeto de estudio de la investigación, y por último, 3) el planteamiento de una propuesta metodologica para procesos de vinculación de datos de cara a los recursos digitales abiertos, analizando los hallazgos encontrados para su aplicación en entornos educativos.
Agradecimientos
Esta investigación se lleva a cabo en el marco de la formación doctoral en Ingeniería, en la Universidad Distrital Francisco José de Caldas. De igual forma, la temática planteada se configura como una línea de investigación de Grupo GIIRA.
Referencias
[1] T. Berners-Lee, C. Bizer, T. Heath, “Linked data-the story so far”. International Journal on Semantic Web and Information Systems”, vol. 5, pp. 1-22, 2009.
[2] S. Dietze, H. Yu, D. Giordano, E. Kaldouidi, N. Dovrolis, D. Taivi, “Linked Education: Interlinking Educational Resources and the Web of Data”. 27th annual ACM symposium on Aapplied Computing, pp. 366-371, 2012. [En línea]. Disponible en: http://oro.open.ac.uk/31077/.
[3] B. Haslhofer, A. Isaac, “Data. europeana. eu: The Europeana Linked Open Data Pilot ”. International Conference on Dublin Core and Metadata Applications, pp. 94-104, 2011. [En línea]. Disponible en: http://dcpapers.dublincore.org/pubs/article/view/3625/1851.
[4] D'Aquin, M. et al ., “Building the Open Elements of an Open Data Competition ” D-Lib Magazine, vol. 20, p. 3, 2014. [En línea]. Disponible en: http://www.dlib.org/dlib/may14/daquin/05daquin.html.
[5] L. Project, “Linking Web Data for Education”. [En línea]. Disponible en: http://linkedup-project.eu/
[6] G. Klyne, J. Carroll, “Resource Description Framework (RDF): Concepts and Abstract Syntax”. 2006. Edited by Brian Mcbride. [En línea]. Disponible en: http://www.citeulike.org/group/2170/article/532408.
[7] M. Hausenblas, “Exploiting Linked Data To Build Web Applications ”. IEEE Internet Computing, vol. 13, no 4, p. 68. 2009.
[8] S. Auer, C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak, Z. Ives, “DBpedia: A Nucleus for a Web of Open Data ”. The Semantic Web , Busan, Korea, Springer, 2007.
[9] LOD-Cloud. “The Linking Open Data Cloud Diagram”. S.f. [En línea]. Disponible en: http://lod-cloud.net/.
[10] Datahub, “Datahub Project”. S. f. [En línea]. Disponible en: http://datahub.io/dataset?tags=lod.
[11] Ministerio de Hacienda y Administración Pública, Ministerio de Industria Energía y Turismo, “Plataformas de publicación de datos abiertos”. [En línea]. Disponible en:http://datos.gob.es/sites/default/files/informe-herramientaspublicacion.pdf.
[12] OKF, “Open Knowledge Foundation”. S. f. [En línea]. Disponible en: http://services.okfn.org/
[13] CKAN, “The Open Source Data Portal Software”. S. f. [En línea]. Disponible en: http://ckan.org/.
[14] CKAN, “API Guide-CKAN’s API for developers”. S. f. [En línea]. Disponible en: http://docs.ckan.org/en/latest/api/index.html.
[15] CKAN, “Ckan Wiki-CKAN Pages”. S.f. [En línea]. Disponible en: https://github.com/ckan/ckan/wiki/ pages.
[16] J. Wonderlich, “Ten Principles for Opening up Government Information”. 2010. [En línea]. Disponible en: http://sunlightfoundation.com/policy/documents/ten-open-data-principles/.
[17] CKAN, “CKAN API Guide”. S. f. [En línea]. Disponible en: http://docs.ckan.org/en/latest/api/.
[18] J. Winn, “Open Data and the Academy: an Evaluation of CKAN for Research Data Management. (IASSIST 2013)”. 28-31 Mayo 2013. [En línea]. Disponible en: http://eprints.lincoln.ac.uk/9778/1/CKANEvaluation.pdf.
[19] E. Rajabi, S. Sanchez-Alonso, M.-A. Sicilia, “Analyzing broken links on the web of data: An experiment with DBpedia ” . Journal of the Association for Information Science and Technology , vol. 65, no 8, p. 1721–1727, 2014. [Onine]. Disponible en: http://onlinelibrary.wiley.com/doi/10.1002/asi.23109/abstract.
[20] C. Bizer, “The Emerging Web of Linked Data”. IEEE Intelligent Systems, vol. 24, no 5, pp. 87-92, 2009. [Onine]. Disponible en:http://lpis.csd.auth.gr/mtpx/sw/material/IEEE-IS/IS-24-5.pdf .
[21] HPI Institut, “State of LOD Cloud”. 2011. [En línea]. Disponible en: http://lod-cloud.net/state/.
[22] M. Allison, S. Richard, K. Patten, C. Caudill-Daugherty, A. Anderson, “Open Access to Geoscience Data for Exploration and Assessment”. 19 al 25 Abril 2015. [En línea]. Disponible en:http://www.geothermalenergy.org/pdf/IGAstandard/WGC/2015/33032.pdf.
[23] W. Mao, J. Jan, “Visualization of Open Data: a CaseStudy of Climate Data”. 36 Asian Conference on Remote Sensing. 19-23 de Octubre de 2015. Manila, Philippines. [En línea]. Disponible en: http://www.acrs2015.org/listof-accepted-abstracts/.
[24] R. Carvalho, J. Aguiar, J. Rocha, C. Ribeiro, “A Comparision of Research Data Management Platforms: Architecture, Flexible Metadata and Interoperability ”. Junio de 2016. [En línea]. Disponible en: https://www.researchgate.net/publication/303918099 A comparison of research data management platforms architecture flexible metadata and interoperability.
[25] CURE, “Infraestructura semantica basada en el paradigma de datos abiertos para la gestión de investigacion de las universidades españolas”. CRUE Universidades Españolas , 2016. [En línea]. Disponible en:http://tic.crue.org/wpcontent/uploads/2016/07/Memoria-proyecto-H%C3 %A9rcules.pdf.
[26] Datos.gob.es, “Estudio de plataformas tecnologicas datos.gob.es”. S. f. Ministerio de Industria, Turismo y Comercio. [En línea]. Disponible en: http://datos.gob.es/sites/default/files/files/2 cms 01.pdf.
[27] P.A. Gaona-García, C. E. Montenegro y H.W. González, “Hacia una propuesta de mecanismos para la autenticidad de objetos de aprendizaje en plataformas LCMS”. Revista Ingeniería , vol. 19, no 1, p. 50-64.
Licencia
![]()
A partir de la edición del V23N3 del año 2018 hacia adelante, se cambia la Licencia Creative Commons “Atribución—No Comercial – Sin Obra Derivada” a la siguiente:
Atribución - No Comercial – Compartir igual: esta licencia permite a otros distribuir, remezclar, retocar, y crear a partir de tu obra de modo no comercial, siempre y cuando te den crédito y licencien sus nuevas creaciones bajo las mismas condiciones.

2.jpg)