DOI:
https://doi.org/10.14483/23448393.2306Publicado:
2005-11-30Número:
Vol. 11 Núm. 1 (2006): Enero - JunioSección:
Ciencia, investigación, academia y desarrolloAplicación de Algoritmos Genéticos para Localizar un Operador Logístico Maderero en la Localidad de Barrios Unidos, Bogotá D.C., Colombia
Palabras clave:
Algoritmos Genéticos, Operador Logístico, Localidad de Barrios Unidos, Madera, Localización. (es).Descargas
Referencias
César Polanco, John Ayure y Mariela Gómez, «Diagnóstico Ambiental de las Empresas dedicadas a la transformación de la madera en la Localidad de Barrios Unidos, con énfasis en la generación de residuos». Proyecto de Investigación, Universidad Distrital Francisco José de Caldas, Bogotá D.C., Colombia, 2004.
Christian Kleinerman, «Algoritmos Genéticos en la Asignación y Elaboración de Turnos». Tesis Universidad de los Andes, Bogotá D.C., Colombia, 1999, pp. 37.
Wolfgand Kook, «Análisis de Estado del Arte en Algoritmos Genéticos Camero». Tesis Universidad de los Andes, Bogotá D.C., Colombia, 2004.
Steven Nahmias, Análisis de la Producción y las Operaciones. México, 1999, pp. 817.
Larry LeBlanc, et al, «Formulating and Solving Production Panning Problems», European Journal of Operational Research, 112, 1999, pp. 54-80.
Zbigniew Michalewicz, et al, «The use of genetic algorithms to solve the economic lot size scheduling problem», European Journal of Operational Research, 110, 1998, pp. 509-524.
Mauricio Salazar, «Implementación de Algoritmos Genéticos en el problema de Ruteo de vehículos con capacidad limitada», Tesis Universidad de los Andes, Bogotá D.C., Colombia, 2004, pp. 49.
Tim Duncan, «Experiments in the use of Neighbourhood Search techniques for Vehicle Routing». Technical Report AIAI-TR176, Artificial Intelligence Applications Institute, University of Edinburgh, 1995.
C. Reeves, editor. «Modern Heuristic Techniques for Combinatorial Optimisation», Blackwell Scientific Publications, Oxford, 1993.
Cómo citar
APA
ACM
ACS
ABNT
Chicago
Harvard
IEEE
MLA
Turabian
Vancouver
Descargar cita
Ciencia, Investigación, Academia y Desarrollo
Ingeniería, 2006-00-00 vol:11 nro:1 pág:16-25
Aplicación de Algoritmos Genéticos para Localizar un Operador Logístico Maderero en la Localidad de Barrios Unidos, Bogotá D.C., Colombia
César Polanco Tapia
Coordinador del Laboratorio de Tecnología de Maderas, Facultad de Medio Ambiente y Recursos Naturales, Universidad Distrital Francisco José de Caldas.
Resumen
Este artículo presenta un algoritmo genético, para resolver el problema de localización de un Operador Logístico maderero, en la localidad de Barrios Unidos (Bogotá D.C., Colombia). El modelo de optimización empleado, incluyó la demanda anual de 270 clientes, la distancia entre las unidades barriales seleccionadas, así como los costos de transporte asociados en un único modo de transporte, además de los costos de apertura del operador.
En la implementación del algoritmo genético se variaron las probabilidades de cruce, de mutación, el número de generaciones, así mismo se trabajaron cinco instancias de problemas (5, 10, 15, 20 y 26), correspondientes al número de barrios tenidos en cuenta para emplazar el operador logístico.
Palabras clave: Algoritmos Genéticos, Operador Logístico, Localidad de Barrios Unidos, Madera, Localización.
Abstract
This paper presents a genetic algorithm, to solve the problem of localization of a lumberman Logistical Operator, in the Barrios Unidos Locality (Bogotá D.C., Colombia). The used pattern of optimisation included the annual demand of 270 clients, the distance among the selected zones, as well as the costs of an only way of transport, besides the opening costs of the operator.
In the genetic algorithm implementation, the crossing and mutation rates were varied, the number of generations, likewise five instances of problems were worked corresponding to the number of neighbourhoods (5, 10, 15, 20 and 26). These were kept in mind to summon the logistical operator.
Key words: Genetic Algorithms, Logistical Operator, Barrios Unidos Locality, Wood, Localization.
1. INTRODUCCIÓN
Un problema interesante que surge a la hora de tomar la decisión de crear y montar un almacén, es su localización. Esta ha de reducir los costos asociados al montaje y aquellos relacionados con la distribución hacia los diferentes clientes.
En esta distribución se puede pensar en clientes en otros países, en otras ciudades, en diferentes áreas para una ciudad o incluso para una misma área. También se puede pensar en clientes presentes y/o futuros, por ejemplo para flexibilizar el centro de distribución en el tiempo, pues el número de clientes y su demanda pueden cambiar con el tiempo.
El presente trabajo aborda el problema de localización de uno o varios operadores logísticos en un área de la ciudad de Bogotá D.C., reconocida como la localidad de Barrios Unidos, para asegurar el suministro de madera a 270 establecimientos, al mínimo costo, asumiendo su permanencia y demanda en el mediano y largo plazo.
Para esto se ha tomado la división política por barrios, la cual consiste en 26 áreas. A partir de estas unidades se empleó la metaheurística de Algoritmos Genéticos A.G. para determinar cual o cuales deben ser los lugares más apropiados para el emplazamiento del operador logístico.
Se han tomado datos verídicos [1], apoyados por un sistema de información geográfica (SIG) para el cálculo de distancias, las demandas se determinaron en el año 2004, según información suministrada directamente por las empresas. La decisión por la alternativa algorítmica es simplemente exploratoria, por lo que no se asegura su éxito en todos los tamaños de problemas propuestos.
El orden de presentación corresponde primero a una introducción, objetivos y un breve marco teórico. Después se describe brevemente el problema y se da a conocer la metodología empleada. Por último, se enseñan los resultados, sus análisis, concluyendo y recomendando sobre los aspectos más cruciales.
2. OBJETIVOS
2.1. Objetivo General
A partir de la teoría evolutiva, crear un programa basado en la metaheurística de A.G., para definir la mejor localización de uno o varios operadores logísticos, que se encarguen del suministro de madera en la localidad de Barrios Unidos al mínimo costo.
2.2. Objetivos Específicos
- Verificar el desempeño de los A.G. en un problema de localización para diferentes tamaños o instancias de problema.
- Determinar el comportamiento del Algoritmo, ante la variación sistemática de diferentes parámetros.
- Evaluar la efectividad del programa después de su desarrollo y aplicación, a partir de diseños experimentales con bloques al azar y arreglo factorial.
3. MARCO TEÓRICO
Los A.G. son una analogía de los procesos naturales que gobiernan la evolución de las especies y su adaptación al medio. Como en la naturaleza los A.G. no actúan sobre individuos para dar origen a una nueva generación, la cual es susceptible de cambio por mutaciones, las cuales, a su vez son mucho menos frecuentes que los cruces. Todo esto hace que algunos casos de la vida real, se puedan modelar matemáticamente con esta herramienta encontrando resultados interesantes [2][3].
La investigación de operaciones es un área que ha encontrado grandes beneficios con esta heurística, alcanzando valores apropiados para muchas funciones, las cuales con otras técnicas como la optimización lineal, dejan entrever resultados poco alentadores, por el tiempo que sería necesario para encontrar un valor apropiado en la función objetivo, así sea que se trate de un problema de minimización o de maximización [2][3][4].
En general, para implementar un A.G. se siguen algunos pasos de forma sistemática y se asumen unos supuestos; a partir de analogías ellos son:
Individuos: Conjunción de parámetros que corresponden a una posible solución del problema en cuestión.
Cromosoma: Representación ordenada del individuo, bajo un código amigable con la programación.
Gen: Característica particular que en conjunto tipifican un individuo.
Lugar: Orden de cada gen en el cromosoma.
Población: Conjunto de individuos (cromosomas).
Generación: Corresponde a la iteración dentro de la programación.
Cruce: Combinación de dos o más genes entre par de individuos.
Mutación: Cambio en uno o más genes para un individuo.
Selección: Elección de aquellos individuos que mayor satisfacen la función objetivo.
Todos estos elementos se ponen de manifiesto al implementar la metaheurística de A.G. para un problema particular. Es de anotar que los elementos mencionados con anterioridad no son estáticos o fijos. Una de las ventajas del A.G. es que se pueden cambiar los parámetros de forma sucesiva, obteniendo la posibilidad de seleccionar los que más se ajustan a los objetivos de la solución definitiva del problema.
Entre los parámetros modificables están el tamaño de la población, la población inicial, las probabilidades de cruce, la población que se va a cruzar, la forma de cruce, la probabilidad de mutación, la forma de mutación, el número de generaciones, y si es posible, se puede complementar el algoritmo con otras heurísticas que mejoran su desempeño como las estrategias de vecindad, esto sin mencionar el número de experimentos y la corrección de individuos no aptos, lo cual vuelve más complejo y a la vez más efectivo el desempeño del Algoritmo.
Por la implementación de probabilidades, los A.G. no son una herramienta determinista, sino estocástica, esto junto con el gran nivel de exploración, hacen que las mejores soluciones encontradas no se puedan replicar en el corto plazo para problemas complejos, no así para problemas «pequeños» y «medianos» donde la convergencia se alcanza fácilmente, sin importar grandes diferencias en los parámetros de probabilidad, tamaño de la población y número de generaciones, que son los parámetros de mayor facilidad en su modificación [3].
4. BREVE DESCRIPCIÓN DEL PROBLEMA
A raíz de una investigación en el sector Mueble y Madera en la Localidad de Barrios Unidos [1], se observó la necesidad de crear un Operador Logístico que suministre la madera en las cantidades y calidades exigidas a 270 establecimientos ubicados en la zona; de tal forma que se eleve la competitividad del sector, pues en la actualidad se consumen entre 15.000 y 30.000 m3 de madera al año, a un costo aproximado de diez mil millones de pesos ($ 10'000.000.000), unos US $ 4.500.000, representando este último entre el 30 y 70% de los costos totales de producción. Para el adecuado suministro es necesario seleccionar el área al interior de la localidad que brinde las mejores condiciones geográficas y de transporte para minimizar los costos logísticos relacionados con la distribución. Mediante la heurística de A.G. el autor pretende resolver este problema.
5. METODOLOGÍA
5.1. La Función Objetivo
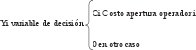
El modelo propone tres variables de decisión a saber:- La distancia total recorrida desde el lugar de emplazamiento del (de los) operador(es) logístico(s) hasta cada centro de transformación, la cual habría que minimizar.
- El costo de apertura del Operador Logístico. Un menor número de operadores a abrir, implica menores costos en la función objetivo.
- Por último la demanda de los centros de transformación y/o consumo, la cual será más favorable entre más grande sea, pues el operador logístico debe ubicarse cerca de aquellos que más consumen, disminuyendo así los costos de transporte.
El modelo pudiera ampliarse teniendo en cuenta las capacidades de cada operador logístico, para satisfacer la demanda de una fracción de consumidores, pero el presente problema no tiene en cuenta limitaciones de capacidad, ya que como estos operadores no existen, es necesario crearlos. Después de resolver la asignación, se determinará el tamaño de el o los posibles operadores logísticos en la localidad, según la demanda de sus clientes asignados.
Para las tres variables de decisión se probaron las siguientes funciones objetivo, enumeradas desde uno hasta seis (1-6).
a. Aquella que minimiza distancias.
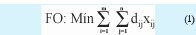
Donde, dij es la distancia desde el o los operadores logísticos i a las fábricas j

b. Aquella que minimiza distancias y costos de apertura.
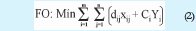
Donde, dij es la distancia desde el o los operadores logísticos i a las fábricas j

Ci Costo apertura operador i
Las dos anteriores ecuaciones, se construyeron para darle prioridad a la distancia, variable que por sí sola no define la o las ubicaciones de los posibles operadores logísticos, ya que se está trabajando en un espacio geográfico pequeño donde hay una marcada concentración de empresas de diferente tamaño y consumo de madera. Adicionalmente, estas diferencias no son tan grandes, que la aplicación del concepto distancia, solo se justificaría si las demandas fueran similares.
c.Aquella que maximiza el suministro.
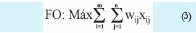
Donde, wij corresponde al consumo de j a ser satisfecho por el operador i

d. Aquella que maximiza el consumo y Minimiza los costos de apertura
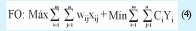
Donde, wij corresponde al consumo de j a ser satisfecho por el operador i

Así como las expresiones (1) y (2), dan exclusiva importancia a la distancia (dij), las ecuaciones (3) y (4), la otorgan a la demanda de cada consumidor, lo cual tampoco sería conveniente ya que favorecería a aquellos con consumo individual alto, sin importar si un conglomerado de establecimientos lidera el consumo para la localidad.
Por este conjunto de razones se determinó usar todas las variables de decisión conjuntamente como se muestra en las expresiones (5) y (6).
e. Aquella que minimiza la distancia y el consumo, conjuntamente con el costo de apertura.
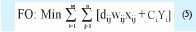
dij: distancia a recorrer desde el operador i a la fábrica j (m)
wij: consumo a despachar desde el operador i a la fábrica j (m3/año)
Ci : Costo de apertura del operador logístico i ($)


Esta opción favorece la localización de aquellos lugares con menor demanda, lo cual no es conveniente, pues se sacrifican distancias al momento de distribuir a los más grandes, sobretodo en trayectos largos.
f. Debido a la función anterior y sus inconvenientes, se planteó la siguiente opción.
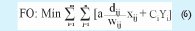
a : Costo de transportar madera procesada ($.m3/m)
dij: distancia a recorrer desde el operador i a la fábrica j (m)
wij: consumo a despachar desde el operador i a la fábrica j (m3/año)
Ci : Costo de apertura del operador logístico i ($)


Después de algunas pruebas, se comprobó la eficiencia de está última función, para todos los casos, por lo cual se adoptó para el modelo final.
Para llevar control de los valores reportados después de las corridas se asumieron valores muy grandes para el costo de apertura y valores menores para el costo de transporte, en todos los casos los valores adoptados son una muy buena aproximación a la realidad.
Además, esta función privilegia a aquellos sitios que reducen la distancia total o que están más cerca de todos los demás. Así mismo, favorece de forma simultánea los que poseen mayor demanda, pues la distancia a recorrer equivale a cero cuando el Operador Logístico se ubica en el mismo barrio de los consumidores. Por las características de las variables, la relación dij/wij se tomó como adimensional. Por lo demás, el costo de apertura se mantiene constante para todos los centros que se abren.
5.1.1. Restricciones
a. Cada centro de consumo (cliente) debe ser atendido por un único operador logístico.

b. La demanda de los clientes j debe ser satisfecha por los operadores logísticos asignados i.
Como el problema es de asignación, en esta restricción se asumió que cada operador logístico era capaz de satisfacer la demanda de los clientes asignados.
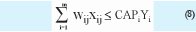
Donde, CAPi es la capacidad de suministro del Operador Logístico.
c. Uno (1) y cero (0), para el caso que el operador atienda al cliente en cuestión, ya sea que se abra o no.
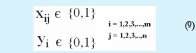
5.1.2. Modelo Final
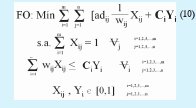
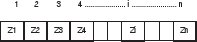
5.2. Representación
El cromosoma posee n genes correspondientes a n sitios posibles de instalación del Operador Logístico. Los valores de Zi obedecen al número del Operador Logístico que lo surtirá, que no es más que el código de su ubicación.
5.3. Obtención de la Información Base
5.3.1. Cálculo de las Demandas
Las demandas de madera anual, oscilan entre 15.000 y 30.000 m3 en la localidad cuando se toman de manera agregada, por lo que se asumió un valor medio de 22500 m3/año, obviando oscilaciones por condiciones de la economía o fluctuaciones de demanda por los consumidores finales. En cualquier caso, este dato se mantuvo fijo para todos los ejercicios.
5.3.2. Localización de los Establecimientos
Al momento de la encuesta, se corroboró la dirección de cada centro de transformación, con la ayuda de un Sistema de Información Geográfica (SIG), se procedió a ubicar todos lo puntos en un mapa digital de Bogotá D.C. bajo la plataforma ArcView 3.0 ®, igualmente se digitalizaron las calles y avenidas, las manzanas y los barrios, entre otros.
5.3.3. Cálculo de Distancias
Con la ubicación de todos los clientes en el SIG, se procedió a medir las distancias, respetando el sentido de las calles, de cada cliente a todos los demás. Después de varias mediciones, se notó que la operación era bastante dispendiosa, por lo que se desecho la idea de distancias entre clientes.
Como el objeto del estudio es conocer la mejor localidad para establecer el operador logístico, se optó por el barrio como la mejor unidad, por dos razones básicas:
- el nivel exploratorio del presente estudio y
- la facilidad en la medición de distancias.
Con la herramienta measure, se calculó la distancia de barrio a barrio, partiendo del mismo centro de gravedad [5], según la densidad de establecimientos, y siguiendo las rutas que a criterio del autor son las más aconsejables para el transporte de madera.
5.3.4. Construcción del Código de Programación
Siguiendo el procedimiento de Metaheurísticas, se configuró el código en Visual Basic, para la función objetivo planteada y su restricción a través de A.G. [5][6]. Se aplicó el siguiente esquema.
- Generar población inicial A través de una asignación aleatoria el algoritmo asigna 1 o 0 en todas las posiciones (genes) de los cromosomas.
- Evaluar la idoneidad de cada cromosoma Para cada cromosoma de la población actual se evalúa la función objetivo
- Calcular el mejor y el peor valor De acuerdo a los resultados del paso anterior, el algoritmo busca y guarda el mejor y el peor valor. También guarda el cromosoma que generó la mejor solución.
- Selección Ruleta La selección ruleta consta de tres pasos, primero se generan ciertas probabilidades de selección de acuerdo al valor de la función objetivo de cada uno de los cromosomas; los cromosomas con mejores valores tienen mayor probabilidadde ser elegidos y continuar dentro de la población. Luego de acuerdo a las probabilidades se generan números aleatorios y se seleccionan los cromosomas que siguen en la población. Por último se obtiene la población nueva, de acuerdo a los cromosomas seleccionados.
- Cruce de individuos Se genera un número aleatorio entre 0 y 1 por cada cromosoma, si este número es menor a la probabilidad de cruce el cromosoma es seleccionado para ser cruzado. Los cromosomas seleccionados para cruce luego entran a un proceso en el cual a través de números aleatorios se generan parejas de padres a cruzar. Finalmente, estas parejas entran en una subrutina en la cual se genera un número aleatorio que indica en que punto deben ser cortados los cromosomas, los cromosomas son cortados y las últimas partes son intercambiadas.
- Mutación Se genera un número aleatorio entre 0 y 1, si el número es menor a la probabilidad de mutación el gen (de todos los evaluados) debe cambiarse, por un nuevo valor de ubicación del operador logístico.
- Asignar población nueva De acuerdo a los cruces y mutaciones que se llevaron a cabo, se define la nueva población y en caso que el número total de iteraciones no se haya alcanzado, retorna al punto 2.
5.4. Tamaños de Problema (n)
Con el fin de evaluar el desempeño del A.G., se contemplaron cinco tamaños de problema, equivalentes al número de barrios involucrados, estos tamaños fueron: 5, 10, 15, 20 y 26.5.5. Selección y Variación de los Parámetros del Modelo
5.5.1. Probabilidad de Cruce (Pc)
Se escogieron tres probabilidades de cruce 0.25, 0.5 y 0.75, que abarcarán el conjunto de posibilidades entre 0 y 1. Al final cuando se notó la ausencia del óptimo en los resultados finales, se afinó este valor de probabilidad siendo muy conveniente este procedimiento en los problemas de tamaño 20 y 26.
5.5.2. Probabilidad de Mutación (Pm)
Al igual que la probabilidad de cruce, la probabilidad de mutación se estableció para tres valores 0.01, 0.05 y 0.1, identificando el mejor comportamiento de esta probabilidad en cada corrida. Al igual que en el caso anterior, el valor de esta probabilidad se afinó, mejorando los resultados para los problemas de tamaño 20 y 26.
5.5.3. Número de Generaciones (G)
Para evaluar el efecto del aumento del número de generaciones, para cada combinación entre la probabilidad de cruce y mutación, se adoptaron diferentes valores como 30, 60, 120, 500 y 1000, en todos los casos. Cuando el número de generaciones y los demás parámetros no permitieron alcanzar el valor óptimo, se aumentó el número de generaciones a 2000, 4000, 8000, 16000 y en los casos más extremos a 32000.
5.5.4. Tamaño de la Población y Número de Experimentos
Estos parámetros se conservaron constantes durante todo el proceso. No se modificaron debido a que esta vez el autor le dio mayor preponderancia a la variación del número de generaciones para el mejor desempeño del algoritmo, se registró el tiempo computacional y se grabó en las hojas de salida de EXCEL. El tamaño de población fue de 30 y 30 fueron también los experimentos realizados en cada iteración.
5.6. Diseño Experimental
Se implementó un diseño en bloques al azar con arreglo factorial de tres variables, cada una, para la probabilidad de cruce y mutación, seleccionando la mejor combinación de parámetros y determinando si existían o no, diferencias significativas entre tratamientos al 95% y 99.9% de probabilidad. También se midió la interacción entre los dos tipos de probabilidad trabajados.
El diseño experimental se probó en una tabla de ANOVA, con los valores de suma reportados por cada corrida para los treinta experimentos que reportaron el mejor valor de la función objetivo.
6. Resultados
6.1. Localización de Establecimientos
Se muestra en la Figura 1 la vista general de la localidad con las ubicaciones de cada futuro cliente del operador logístico. Como se puede apreciar, existe una marcada concentración de establecimientos en la parte central, lo que permite aventurar cual debe ser el área a contener el centro de distribución, si la demanda de estos clientes es significativa en conjunto.

La Figura 2 muestra en detalle la ubicación de cada establecimiento por manzana y por predio. Inicialmente y al descartar la opción de distancias entre establecimientos, se contempló la posibilidad de distancia entre manzanas, pero como se puede apreciar en esta figura, representa un problema de alta complejidad por el gran número de manzanas involucradas.
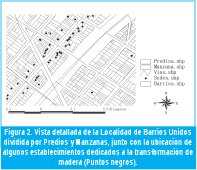
6.2. Demanda de Madera en la Localidad de Barrios Unidos
Como se ya explicó en la metodología, el problema resulta bastante engorroso cuando se trabaja con las demandas de los clientes particulares. Si se hubiere hecho así, el algoritmo indicaría cual cliente, por su ubicación y demanda, podría a futuro convertirse en un operador logístico que asuma su propio abastecimiento y el de sus vecinos, al interior de la localidad. Para tener una idea de la complejidad de este problema, con 270 establecimientos, se tiene un total de 270270 posibles soluciones, que el algoritmo genético tendría que evaluar de forma aleatoria, reduciendo su eficiencia innecesariamente.
Como este problema de localización es exploratorio, conocer el Barrio donde se establecerá la instalación, será suficiente a este nivel. En la Tabla I se dan a conocer las demandas de madera de cada Barrio junto con la sumatoria de las distancias desde cada barrio a todos los demás. El lector puede darse una idea con esta información de cual es el Barrio con mayor predominio de la actividad maderera en la Localidad.
6.3. Variación de las Probabilidades de Cruce y Mutación
En el caso donde el número de barrios es de cinco (5), cualquier combinación de estos parámetros es suficiente para encontrar el valor óptimo. Así se puede corroborar en la Tabla IV. Una medida de desempeño para la selección de la mejor combinación de parámetros, la constituye las desviaciones estándar obtenidas para este tamaño de problema, de esta forma resultan mas convenientes las probabilidades de mutación y cruce mas altas, es decir 0.1 y 0.75, respectivamente.
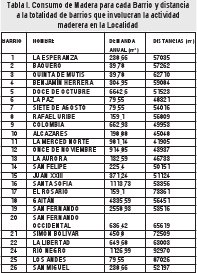
En este caso, el mejor resultado se reporta cuando se ubica un solo establecimiento en el Barrio cinco (5), el cual se constituye como el de mayor demanda de madera de la Localidad. Si se observa la Figura 1, se nota el efecto diluido de la distancia, lo que ratifica la conveniencia del modelo implementado.
En los problemas n=10 y n=15, se da una mayor tendencia de los mejores resultados hacia los valores de probabilidad de mutación bajos. Siendo casi indiferente el valor de probabilidad de cruce.
Para los demás casos (n=20, n=26), no se observa una clara tendencia de la mejor combinación de estos valores de probabilidad. Situación atribuible al carácter estocástico de los modelos, no obstante las menores probabilidades de mutación reportan los mejores resultados.
Al revisar los Diseños Experimentales y las Tablas de ANOVA, se comprueba la ausencia de significancia de la probabilidad de cruce para aquellos problemas donde n=5, es decir que esta variable es indiferente al momento de determinar los mejores valores. Tan solo cuando el número de generaciones es muy grande (250), la probabilidad de cruce entra a jugar un papel diferenciador en la respuesta encontrada a un nivel de probabilidad del 95%. Ver Tabla II.
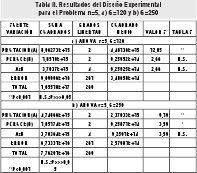
Para los problemas de tamaño 10 las probabilidades en cuestión no intervienen en los resultados obtenidos para un bajo número de generaciones, Tabla III a). Solo cuando se aumenta el número de generaciones, por encima de 120, las probabilidades empleadas confieren diferencias significativas a los tratamientos. Tabla III b).
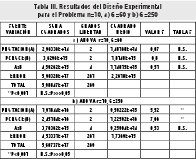
En el problema n= 15, para la mayoría de los casos las probabilidades adoptadas resultan fundamentales como factor diferenciador entre los diferentes tratamientos. Las corridas con 120 generaciones no reportan diferencias significativas entre tratamientos.
Los problemas n= 20 y n= 26, presentan diferencias significativas para todos los tratamientos implementados aunque con cambios en el nivel de significancia sobre todo para la probabilidad de cruce, cuya variación reporta menores diferencias entre los tratamientos.
6.4. Variación del Número de Generaciones
El número de generaciones fue el factor diferenciador para los diferentes tamaños de problema donde se llegó a una solución apropiada, los resultados expresados en la Tabla IV lo muestran. Para las instancias pequeñas y medianas (n=5, n=10, n=15), se encontró el mejor valor al variar las generaciones desde 30 hasta 500. Así para el tamaño n=5 se encontró el mejor valor en 30 generaciones, para n=10 en 120 y para n= 15 en 500 generaciones.
Los problemas de tamaño 20 y 26 no encontraron el valor óptimo de la función objetivo, incluso cuando el total de generaciones se elevo a 1000; a pesar de esto, fue clara la reducción del mejor valor encontrado con el aumento de este parámetro.

6.5. Mejores Resultados Encontrados
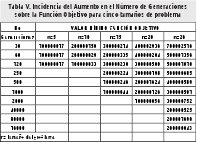
Después de seguir el procedimiento convencional para todos los tamaños del problema, se practicaron sintonizaciones en las probabilidades de mutación y cruce en aquellos tamaños que no alcanzaron el óptimo en la función objetivo (n=20 y n=26). Como resultado, ninguno de los problemas llegó al mejor valor. Por lo cual se decidió aumentar el número de generaciones hasta encontrar un valor cercano al óptimo. Para los tamaños 20 y 26 se corrieron problemas con 2000, 4000, 8000, 16000 y 32000 generaciones, mejorando en el tamaño 20, el valor de la función objetivo, el cual coincidía con el valor óptimo esperado; en este último caso, tan solo 2000 generaciones fueron necesarias. Para el problema de tamaño 26, ninguna de las nuevas generaciones corridas sirvió para llegar al valor óptimo, por lo cual es el único tamaño que funciona con dos centros de distribución. En la Tabla V, se da a conocer el efecto del aumento en el número de generaciones sobre el mejoramiento de la función objetivo para diferentes instancias de problema.
6.6. Tiempo Computacional
El tiempo computacional obtenido para todas y cada una de las corridas, se relacionó estrechamente con el número de generaciones y el tamaño del problema implementado, así por ejemplo, las corridas de 30, 60 y 120 generaciones tardaron entre 7-38, 15-76, 29-152 segundos, respectivamente; mientras que las corridas de 1000, 2000 y 16000 tardaron entre 454-1258, 1386-2466 y 10950-19557 segundos, respectivamente.
Dependiendo del criterio del investigador, se optará por otro procedimiento metaheurístico si se considera que los tiempos son demasiado altos, en cualquier caso la decisión dependerá de las alternativas presentes y los objetivos del estudio [7].
7. ANÁLISIS DE RESULTADOS
Los A.G. implementados para resolver el problema de asignación para los tamaños de problema 5, 10, 15 y 20, resultaron eficientes, en la medida en que para cada uno de estos casos, se alcanzó el valor óptimo, el cual corresponde a la apertura de un operador logístico en el Barrio número 5, Doce de Octubre.
Por su parte, las probabilidades de mutación y de cruce no aseguran que se encuentre el mejor valor de la función objetivo a menos que se aumente considerablemente el número de iteraciones. A pesar de que la probabilidad de mutación fue más importante al momento de generar diferenciación entre los tratamientos para todos los tamaños de problema expuestos, su tendencia hacia valores más bajos indica que este procedimiento cuando se practica, ocasiona saltos que van en contra-posición con el mejor valor encontrado. Así por ejemplo, la probabilidad de encontrar un gen que haga falta dentro del cromosoma equivale a 1/n, siendo n el tamaño del problema, y en la medida en que este aumenta, la probabilidad disminuye junto con el hecho de que todos los genes correspondan a un único valor, cuando se quiere abrir un solo operador logístico o centro de distribución.Por lo anterior resulta más conveniente estimular la probabilidad de cruce cuando se quiere abrir un número bajo de centros de distribución y aumentar la probabilidad de mutación para cuando se desea abrir varios centros de distribución.
De otro modo, resulta conveniente cuando se maneja un número plural de variables de decisión en el modelo, hacer seguimiento a los valores obtenidos en la función objetivo, para cada uno de ellos, como se implementó en el presente trabajo. Asignar un costo de apertura alto ($ 100'000.000) determinó el fácil seguimiento al número de centros de distribución que se deberían abrir. Así mismo, bajos valores asignados a las variables de decisión: distancia y consumo, permitirán, de forma paralela, hacer seguimiento al desempeño del Algoritmo para estas características, ahorrando tiempo en la evaluación de la función objetivo.
Pese a haber comprobado la efectividad del aumento en el número de generaciones, esto no significó una obtención de mejores resultados. Así se corroboró cuando se corrieron 32000 generaciones para los tamaños 20 y 26, donde los mejores valores de la función objetivo, no superan a los mejores valores obtenidos con 2000 generaciones.
La ausencia en la programación del Algoritmo de un procedimiento que obligará a un operador logístico, a satisfacer la demanda del barrio donde se instalase, implicaba un universo innecesariamente más grande en las posibles soluciones, pues no tiene sentido abrir un operador logístico en un área para atender la demanda de otras y que la propia sea abastecida por otro operador, pues no asegura una minimización de la distancia recorrida.
Otro elemento que afectó la eficiencia del Algoritmo fue la ausencia de un operador de vecindad después de las corridas, el cual ha sido muy efectivo para resolver muchas instancias de problemas, por ésta y otras metaheurísticas [8].
8. CONCLUSIONES Y RECOMENDACIONES
La aplicación de A.G. al problema de asignación de operadores logísticos a diferentes clientes, resultó ser una herramienta válida para las instancias planteadas y según la programación implementada. Para instancias superiores, se debe implementar un postprocesador y algunos procedimientos dentro de la programación que agilicen la búsqueda de la mejor solución, como se explicó en el análisis de resultados [8][9].
Una vez conocida la mejor localización para el operador logístico, se debe iniciar un procedimiento similar, ya no con barrios sino con manzanas, para determinar la ubicación más óptima, si esta depende exclusivamente de la distancia recorrida, la demanda y los costos de apertura.
En este caso el modelo matemático castigó la apertura de varios centros de distribución, con valores altos, sin embargo, para problemas donde se trate de abrir operadores en diferentes sitios, donde las condiciones de transporte sean muy costosas, perfectamente se puede castigar el costo de apertura y sobre-estimar los costos por desplazamiento. Este el caso para ubicar, por ejemplo, centros de distribución en diferentes continentes, países e incluso en un mismo territorio nacional, cuando el único medio de transporte es aéreo.
9. REFERENCIAS BIBLIOGRÁFICAS
[1] César Polanco, John Ayure y Mariela Gómez, «Diagnóstico Ambiental de las Empresas dedicadas a la transformación de la madera en la Localidad de Barrios Unidos, con énfasis en la generación de residuos». Proyecto de Investigación, Universidad Distrital Francisco José de Caldas, Bogotá D.C., Colombia, 2004.
[2] Christian Kleinerman, «Algoritmos Genéticos en la Asignación y Elaboración de Turnos». Tesis Universidad de los Andes, Bogotá D.C., Colombia, 1999, pp. 37.
[3] Wolfgand Kook, «Análisis de Estado del Arte en Algoritmos Genéticos Camero». Tesis Universidad de los Andes, Bogotá D.C., Colombia, 2004.
[4] Steven Nahmias, Análisis de la Producción y las Operaciones. México, 1999, pp. 817.
[5] Larry LeBlanc, et al, «Formulating and Solving Production Panning Problems», European Journal of Operational Research, 112, 1999, pp. 54-80.
[6] Zbigniew Michalewicz, et al, «The use of genetic algorithms to solve the economic lot size scheduling problem», European Journal of Operational Research, 110, 1998, pp. 509-524.
[7] Mauricio Salazar, «Implementación de Algoritmos Genéticos en el problema de Ruteo de vehículos con capacidad limitada», Tesis Universidad de los Andes, Bogotá D.C., Colombia, 2004, pp. 49.
[8] Tim Duncan, «Experiments in the use of Neighbourhood Search techniques for Vehicle Routing». Technical Report AIAI-TR176, Artificial Intelligence Applications Institute, University of Edinburgh, 1995.
[9] C. Reeves, editor. «Modern Heuristic Techniques for Combinatorial Optimisation», Blackwell Scientific Publications, Oxford, 1993.
César Augusto Polanco Tapia
Ingeniero Forestal, Universidad Francisco José de Caldas. Especialista en Ingeniería de Producción, Universidad Distrital Francisco José de Caldas. Aspirante a Magíster en Ingeniería Industrial, Universidad de los Andes. Docente Ingeniería Forestal, Universidad Francisco José de Caldas. cpolanco@udistrital.edu.co
Creation date:
Licencia
![]()
A partir de la edición del V23N3 del año 2018 hacia adelante, se cambia la Licencia Creative Commons “Atribución—No Comercial – Sin Obra Derivada” a la siguiente:
Atribución - No Comercial – Compartir igual: esta licencia permite a otros distribuir, remezclar, retocar, y crear a partir de tu obra de modo no comercial, siempre y cuando te den crédito y licencien sus nuevas creaciones bajo las mismas condiciones.

2.jpg)